Cryptanalysis of Meow Hash
By Peter Schmidt-Nielsen
Meow hash
Meow hash is a fast keyed hash function, on GitHub here. At time of writing, Meow hash has 1.2k stars and has several community ports to other languages. Its main design goal is to be extremely fast on processors with hardware AES acceleration, operating at memory bandwidth speeds on large inputs (≥ 50 GiB/s), with relatively low overhead on small inputs as well.
The creators make a few security claims; we will break them all. In particular, we present three main attacks:
- A pair of messages that collide under a random key with probability \(\approx 2^{-45}\), rather than the \(2^{-128}\) they should for a secure hash. This alone breaks Meow hash’s claimed security notion.
- We will examine a threat model in which an attacker can make queries testing if the lowest order bit of the hashes of a pair of messages collide under an unknown secret key. This models attacking a remote hash table where the attacker can detect a collision in hashes from timing. We will show that even in this extremely restricted model an attacker can recover the full 1024-bit key using \(\approx 2^{49}\) queries and negligible additional computation.
- Once the key is recovered, we present attacks based on SAT solving that allow us to construct collisions between arbitrary messages of the same length by appending a small amount of data. I give a pair of PNG files that collide under the default key.
If you want to skip right to the best part, with an interactive demo of differential cryptanalysis, click here.
Meow hash’s cryptographic claims
But first, what sort of security do the Meow hash folks even claim? Initially they disclaim any cryptographic security:
The Meow hash is not designed for cryptography and therefore we make no claims about its security. Assume it is completely insecure.
The Meow hash source code begins with a comment stating:
Meow - A Fast Non-cryptographic Hash
However, they also make some cryptographic claims elsewhere. The GitHub repo’s title is “Official version of the Meow hash, an extremely fast level 3 hash”, they link to their taxonomy of hash function security levels. For a keyed hash function to qualify as “level 3” in this taxonomy requires an adversary to have no advantage over generic attacks on several games (e.g. produce a valid message/hash pair for an unknown key; recover the key given black box access, etc). They explicitly acknowledge the cryptographic nature of these claims, summarizing with:
Level 3 hashes can also be used for hash maps, and suffer no theoretical deficiency for this job. They can also be used for generating message authentication codes, and are therefore usually called MAC functions.
They explicitly write that Meow hash is designed/suitable for level 3 uses:
Q: What is it GOOD for?
A: […] It is fast on all buffer sizes, and can generally be used anywhere you need fast Level 3 hashing […]
Q: What is it BAD for?
A: Anything requiring Level 4 or Level 5 security guarantees (see http://nohatcoder.dk/2019-05-19-1.html#level3) Also, note that Meow is a new hash and has not had the extensive community cryptanalysis necessary to ensure that it is not breakable down to a lower level of hash, so you must do your due diligence in deciding when and where to use Meow instead of a slower but more extensively studied existing hash. We have tried to design it to provide Level 3 security, but the possibility of the hash being broken in the future always exists.
On a GitHub issue, written by one of the designers:
[…] Meow is now designed to be a Level 3 hash (eg., actually secure for an unknown seed [key] and hardened against seed recovery).
This is the same security notion targeted by the extremely popular SipHash, which is widely used to implement DOS-resistant hash tables. So while they mostly disclaim security, they also claim specific cryptographic properties, and the suitability of the hash function as a MAC (Message Authentication Code); albeit, the cryptographic disclaimers are more prominent than the claimers.
Overall I don’t mean to be complaining too much — I suspect most folks will come away understanding that the designers do not endorse using Meow hash as a drop-in substitute for SHA-3, but I’m still a little confused by the conflicting “assume it is completely insecure” and “actually secure for an unknown seed” claims. I do also recognize that they’re attempting to draw a subtle distinction (secure in a MAC setting vs approximating a random oracle) that will likely be lost on most readers, and are erring on the side of saying your toes will fall off if you use Meow hash for crypto.
As we will see, perhaps your toes would fall off.
Cryptanalysis
I group the cryptanalysis into two parts:
- Main attacks: We break all the security claims of their level 3 notion, and also the security claims of their weaker level 2 notion. We will cover, in order:
- Construction: A description of Meow hash.
- Invertibility, symmetry, collisions via symmetry: We will make some high-level observations about Meow hash, and some weird properties. We will show how you can construct collisions under contrived weak keys, although the attack has little practical impact.
- Differential cryptanalysis: We will introduce differential cryptanalysis, and apply it to Meow hash’s absorption function, demonstrating a vanishing characteristic. This vanishing characteristic consists of a set of changes that can be applied to a message and leave the hash unchanged under a random key with probability \(2^{-45}\), rather than the \(2^{-128}\) that would be required of a level 3 hash function. This characteristic is our most important tool, and alone suffices to break Meow hash’s level 3 security claims, and even their weaker level 2 security claims. I give an example of two messages that collide under the default key made using this characteristic.
- Key recovery: We will show how the vanishing characteristic can be used to recover one byte of key at the cost of \(\approx 2^{46}\) hash queries. We will then show how with some additional work and some SAT solving one can recover the entire 1024-bit key at the cost of \(\approx 2^{49}\) hash queries. These key recovery attacks merely require that we be able to query if a pair of messages’ hashes collide in just their lowest bit, and therefore are even possible with just timing against a remote hash table that uses Meow hash.
- SAT solving, making arbitrary messages of the same length collide under a known key: We will show that once the key is known the internal state of Meow hash is readily steerable with SAT solvers. By combining SAT solving with an interesting symmetry property, we will be able to make any two messages of the same length collide under a known key by appending a bit of data to each. I give an example of two PNG files that collide under the default key using this SAT solving+symmetry attack.
- Ancillary attacks and analysis: Finally, at the end of this document I provide some additional analysis and less successful attacks which are possibly of interest to the Meow hash designers in informing fixes, but might not be of broader interest:
- Comparison to other AES-based constructions: We discuss other AES-based hash functions and MACs, and discuss how Meow hash has cut the number of AES rounds to about 25% of what some well-studied constructions aiming for the same level 3 security notion use.
- AES depth: We discuss the depth of Meow hash’s finalization, measured in terms of number of AES rounds.
- Message absorption soundness: We show via SAT solving that Meow hash (simplified, with xors replacing the additions) has no vanishing differential characteristics that involve no active sboxes. This is a good thing. I give a script that the designers of Meow hash can use to sanity check that changes to the design maintain this property.
- Second-order truncated differential cryptanalysis: We present second-order differential cryptanalysis showing biases in a reduced-round version of Meow hash’s finalization that uses only 7 of the 12 rounds.
- Square attack (integral cryptanalysis): We present a square attack showing biases in Meow hash if the finalization were reduced to 5 of the 12 rounds.
- SAT solving, making arbitrary messages of different lengths collide under a known key: We present an attack that seems extremely close to working for producing collisions between arbitrary messages of different lengths using SAT solving under a known key. However, I couldn’t quite get this attack to work so far.
Each cryptanalysis section will be labeled with a tl;dr describing the impact. I categorize impact along two axes:
- Invalidation: Does the section invalidate any of Meow hash’s specific narrow cryptographic claims of being a secure MAC?
- Heebie-jeebies: Is the section high impact in some subjective “this is concerning” sense?
With that in mind, let’s jump in.
Construction
I couldn’t find any existing diagrams or description of how Meow hash v0.5 (current as of 2021-06) works, so I produced the following diagrams and prose from reading their C source.
Meow hash takes a 1024-bit key k, a message of zero or more bytes m, and produces a 128-bit hash MeowHash(k, m).
Very roughly, Meow hash proceeds as follows:
- Initialize a state consisting of eight 128-bit lanes (1024 bits in total) to be equal to the 1024 bits of
k. - Pad the message to the next multiple of 32 bytes with zeros.
- Absorb the message
minto the state in 32-byte blocks, along with a 32-byte block containing the message length. - Apply some finalization rounds.
- Return lane 0 as the 128-bit hash.
The Meow hash designers also provide a default key to be used to treat Meow hash as an unkeyed hash function.
Absorption function
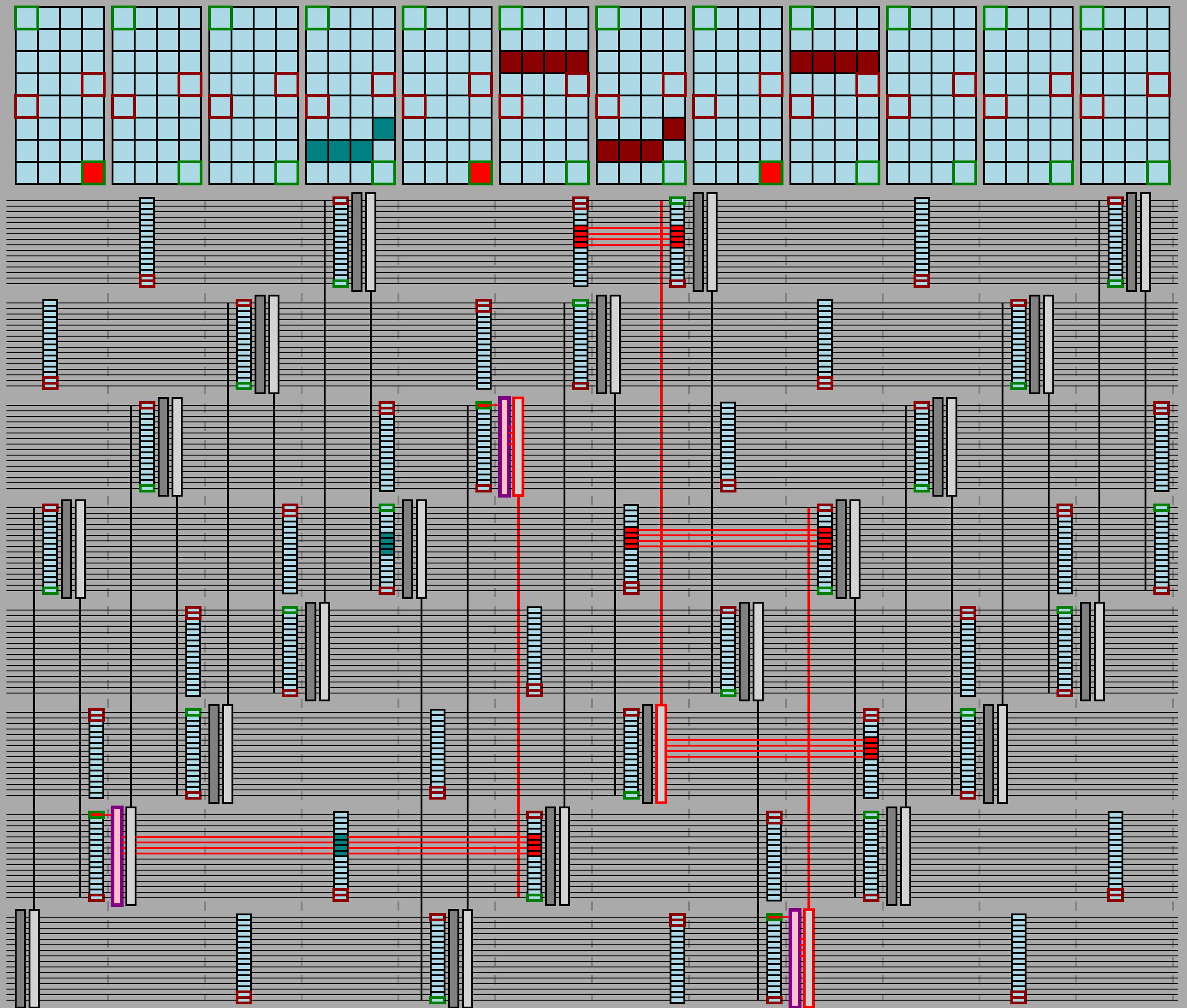
Meow hash is built around one core operation, which they call meow mix, that absorbs a 32-byte message block into Meow hash’s 1024-bit state, diagrammed here:
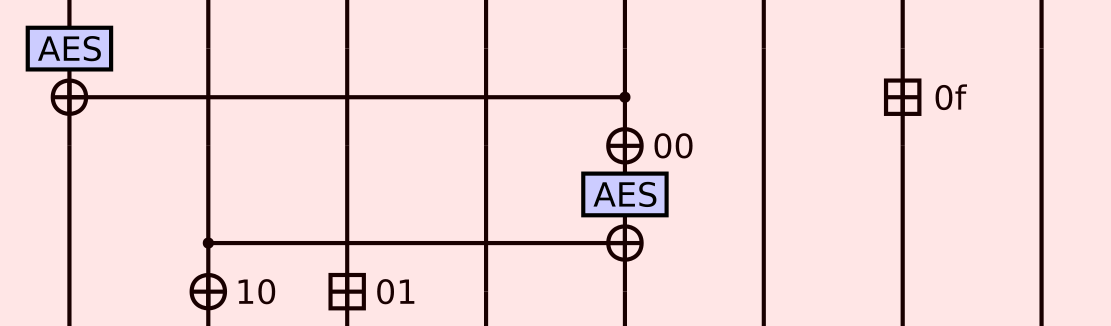
Each of the vertical wires is one of eight 128-bit lanes of Meow hash’s 1024-bit state. The AES blocks correspond to a single round of unkeyed AES decryption (that is, inverse shift rows, inverse sbox, then inverse mix columns, in that order). Each circled plus corresponds to xor, and each boxed plus corresponds to a pair of 64-bit additions (not a 128-bit addition).
You’ll notice that some of the xors and all of the additions have only one incoming wire, but instead an address next to them.
These operations read 128 bits (16 bytes) from the current 32-byte message block starting at the given byte address to get their second operand.
For example, the top right boxed plus with 0f next to it means:
- Read
message_block[0x0f : 0x0f + 16]. - Split the 16 bytes read into a low order 64-bit word and a high order 64-bit word.
- Add the low order 64-bit word into the low order 64 bits of lane 6.
- Add the high order 64-bit word into the high order 64 bits of lane 6.
Thus, one meow mix round applies two AES rounds and incorporates a 32-byte message block via four separate 16-byte reads (offset by 0, 1, 15, and 16 bytes into the block).
Meow hash absorbs inputs by applying one meow mix operation for each 32-byte block of input, with the lanes that the operations are applied to cycling forward by one lane each block. This means that Meow hash naturally has a period of eight 32-byte blocks, and can instead be thought as absorbing 256-byte blocks into the state via the following network of eight meow mixes:
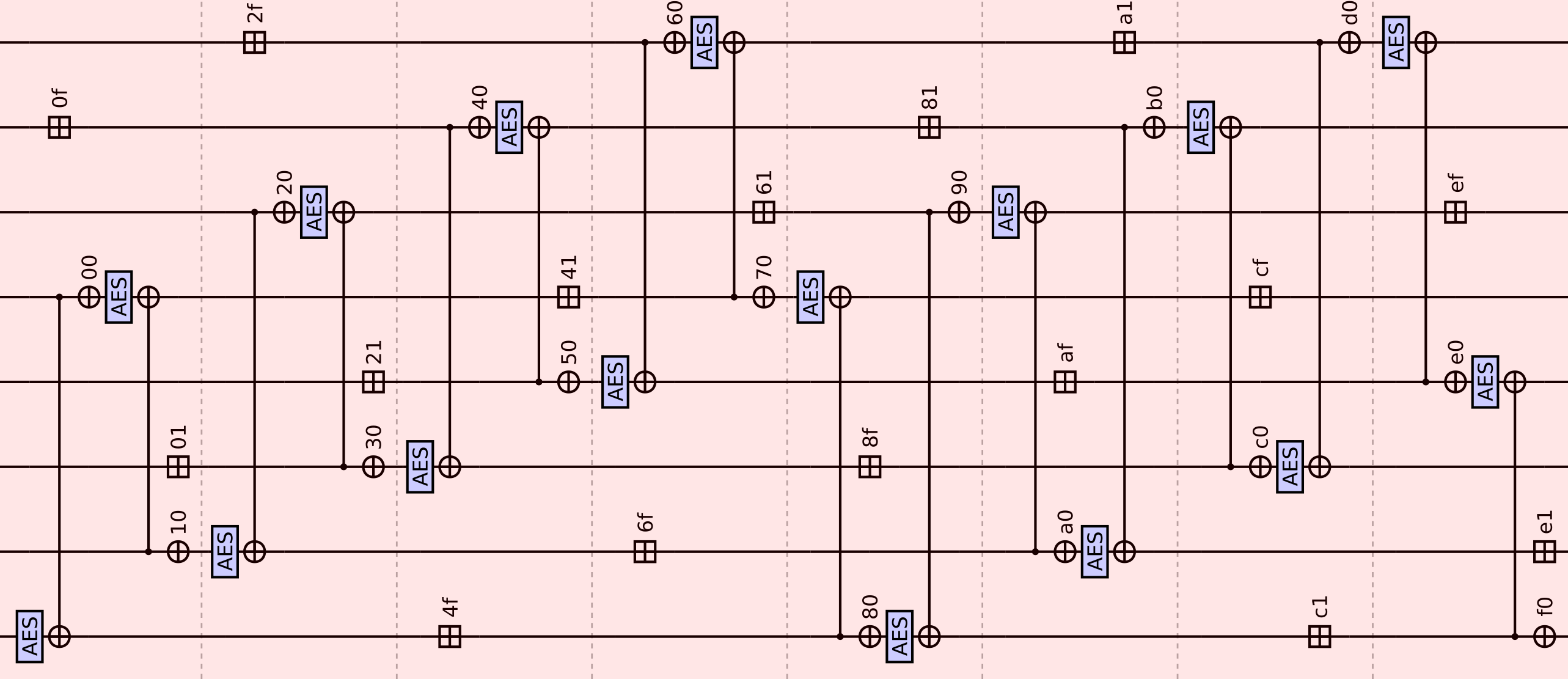
Here the addresses next to the xors and additions are relative to the start of the 256-byte block.
Alternatively, instead of thinking of the data as fixed and the operations as moving, we may describe the absorption function in a shift-register fashion where the data moves and the operations are fixed.

In this description we absorb 32-byte blocks one at a time. For each 32-byte block M we clock the above shift-register once (where “clock” means that each of the eight 128-bit register blocks is assigned the value on the incoming edge).
Finalization rounds
After the entire message is absorbed, we apply the following finalization rounds:
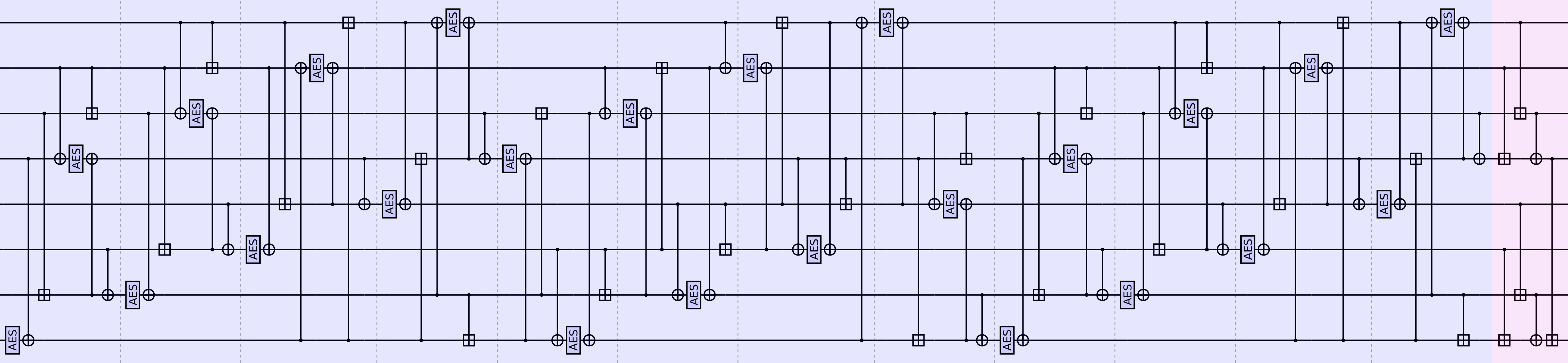
Here the blue part consists of 12 “rounds” that result in each lane receiving three rounds of AES decryption. Finally, the pink part aggregates all the lanes down into a single 128-bit output that is returned as the final hash.
Again, we can phrase (the blue part of) finalization instead as a shift-register:

In this view finalization consists of clocking the above shift-register twelve times.
Padding and absorption order
Meow hash absorbs the message as follows:
- Pad the message up to the next multiple of 32 length by appending zero bytes. I emphasize next, because if the input is already a multiple of 32 bytes we pad it to the next one anyway.
- Split the message into 32-byte blocks.
- Absorb groups of 8 blocks at a time until fewer than 8 blocks remain. However, do not absorb the very last block in this way.
- Absorb1 the very last block.
- Absorb1 a block consisting of the four 64-bit little endian numbers
(0, 0, unpadded message length, 0). - Absorb the remaining unabsorbed blocks (of which there can be at most 7).
This order is a bit unusual, so we diagram it here:
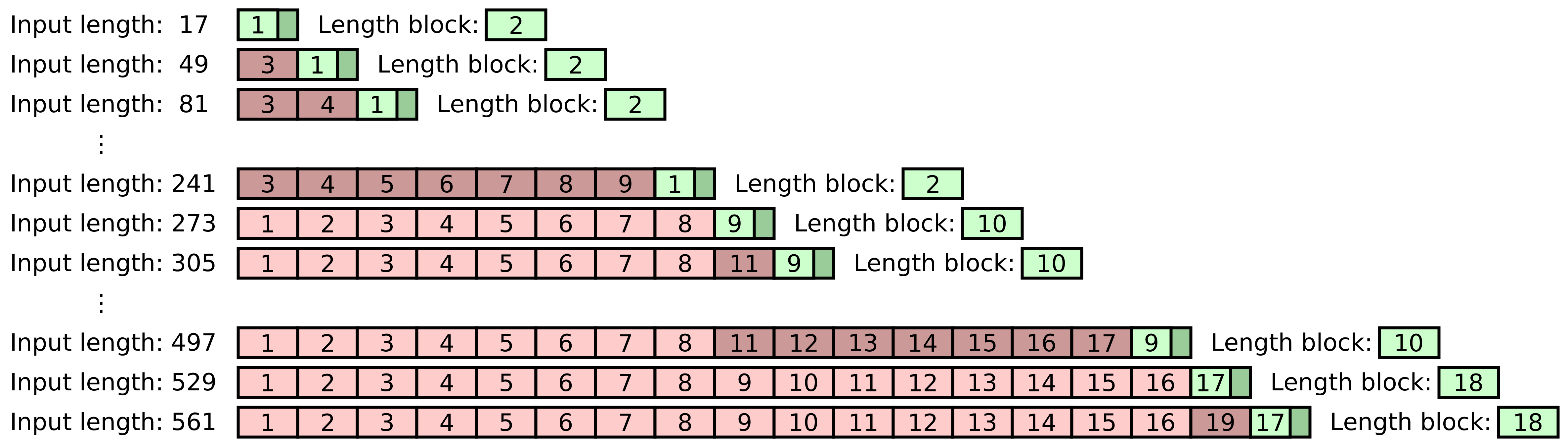
In the above diagram we show the order in which Meow hash would absorb the input message bytes for a variety of possible lengths. Each box represents a 32 byte block, and the number in the box indicates the order in which it is absorbed via Meow mix.
For example, an 81-byte input consists of two complete 32-byte blocks, followed by a 17-byte tail that is padded up to 32 bytes. The tail block is absorbed first, as indicated by the 1 in the green box, then the message length block is absorbed, and finally the two message blocks that precede the tail are absorbed.
Example
As an example, if we were to hash a 256-byte message Meow hash’s entire computation would consist of the following network:

- First, the key is fed in as the initial values on the left.
- The red region absorbs the 256-byte message block by applying eight meow mixes, each absorbing 32 bytes.
- The green region absorbs the padding block (all zeros, in this case), then the message length block.
- The blue region is the finalization rounds.
- The pink region aggregates the state down into a single output lane.
- The final hash value is the output of the bottom lane (lane 0).
For those curious about the details, I provide a reference implementation in Python below in the appendix.
Main attacks
Invertibility
TL;DR: No invalidation, low heebie-jeebies. You can compute a key that sends a message to any hash value you want. This isn’t a weakness, per se, but it’s unusual.
As a first observation, note that for any fixed 32-byte message block meow mix is a permutation, with a readily computable inverse, and the finalization rounds are also invertible. This is extremely common in modern sponge-like hash functions.
However, typically such an invertible construction fixes all or part of the initial internal state, while Meow hash uses the 1024-bit key as the 1024-bit initial state.
This results in a strange affordance: Given a message m and target hash value h, one may compute a key k such that MeowHash(k, m) = h simply by running all the steps of the hash function backward from the output state all the way to the initial state.
For example:
key = hex_to_bytes(
"17180fbeaaaf6095c0b5ebd24f9e9fe9a7aac518ff05b230d29b74137467bc4a"
"a611dfaf465a50c44b0dbf171f6c8242242800c887d20830ff2f96340099f735"
"8590e7f8db60479d6c92cecad24deeef16d19e9ef67a680782dedbf2766587ba"
"f1d9572b0117e02d13c23eadc14a0c1f27a4d6fa9fdb5067241d2488c99beff9"
)
message = (
"Arbitrary example input: Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed"
" do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,"
" quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat."
)
MeowHash(key, message) == "Arbitrary value."Of course it is therefore also possible to generate collisions, albeit ones between different keys.
I wouldn’t call this a “weakness” per se, but it is certainly a surprising affordance in something calling itself a hash function, and deserves a disclaimer. Much as length extension attacks aren’t an outright break in SHA-256, but a bizarre affordance that must be designed around, here the ability to compute key/message pairs that hash to any given target hash value must be considered in any potentially adversarial usage of Meow hash. Certainly if your mental model of a keyed hash function is a family (indexed by the key) of random oracles then this behavior is already a non-ideality.
I should note that that a closely related property is not unheard of in MAC functions: Some MAC functions allow one to steer the state completely with any single message block, and thus one can produce any tag (hash) desired. For example, CBC-MACs, OMACs, and other CBC-MAC-style constructions (such as Chaskey) have this property, as do some Wegman-Carter style MACs, like Poly1305. However, more hash-flavored MACs like SipHash or PELICAN, and other Wegman-Carter style MACs do not admit this affordance. On the other hand, MAC functions with the above property typically don’t allow one to trivially steer the hash to any desired value with control over just the key, like Meow hash does.
(As an amusing aside, my friend Max Justicz noticed this property first, and pointed it out to me — I didn’t notice after a full day of investigating Meow hash.)
Symmetry
TL;DR: No invalidation, medium heebie-jeebies. All the operations used in Meow hash have a symmetry property, which results in a 512-bit invariant subspace in the absorption function. This probably isn’t great, although the directly exploitable consequences are limited. However, we will take advantage of this invariant subspace in later attacks.
Let a 128-bit value be said to be symmetrical if its high and low order 64-bit halves are equal. Meow hash is built entirely from just three operations:
- Apply one round of AES decryption on a 128-bit lane.
- Xor a 128-bit value into a 128-bit lane.
- Add a 128-bit value into a 128-bit lane by adding the low and high 64-bit words elementwise.
Unfortunately, all three of these operations have the property that if the inputs are symmetrical, then the outputs will be as well.
This symmetry is clearly true of xor and addition, but it also ends up being true for AES decryption due to the byte order that the aesdec instruction uses.
In the following diagram see how a symmetrical 16-byte input gets mapped to a symmetrical 16-byte output by one round of AES decryption:
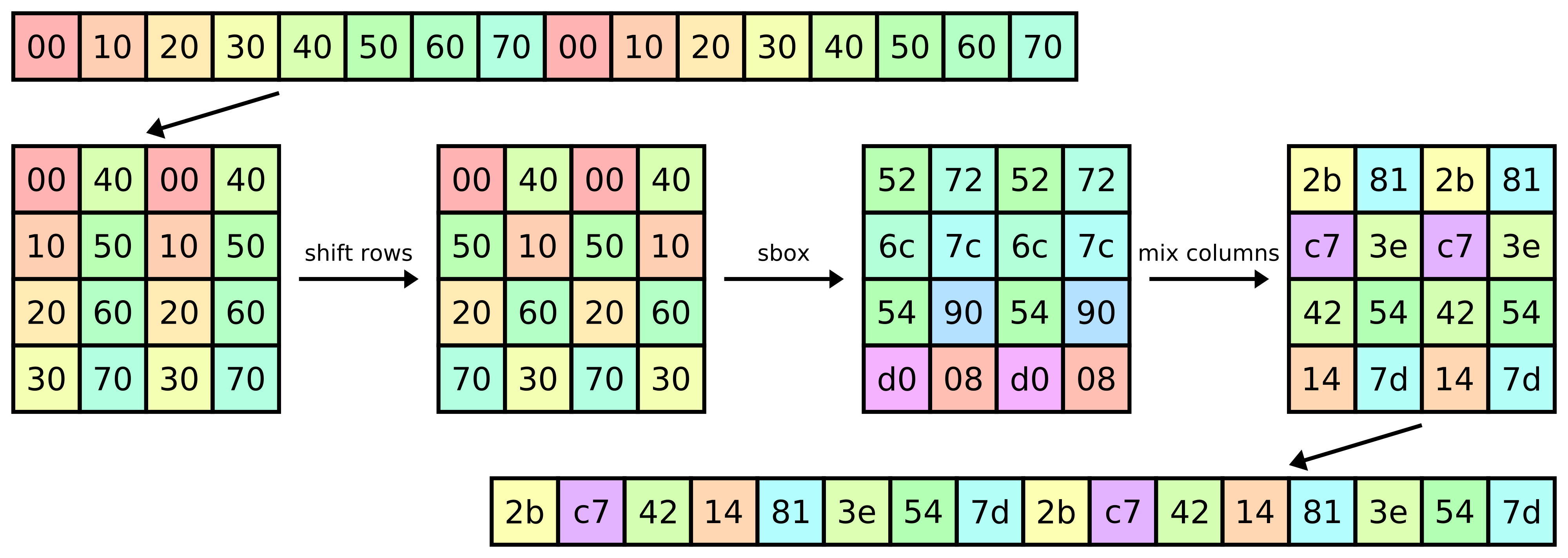
Can we exploit this symmetry in Meow hash? Let a 1024-bit value be said to be symmetrical if each of its 128-bit lanes is symmetrical. If, hypothetically, the state of Meow hash were to become symmetrical, then we can maintain this property in the absorption function by ensuring that each of the reads from the message block is symmetrical.
Let us take a closer look at the message block reads that are performed.
Recall that each meow mix operation absorbs a 32-byte block by making four separate 16-byte reads, starting at byte offsets 0, 1, 15, and 16.
The consequence of this is that if our input message consists of 32-byte blocks of the form abcdefghabcdefghaijklmnhaijklmnh for some bytes a through m, then all reads will be symmetrical, as shown below:

We will call a message of this form an abc-symmetrical message. Thus, if one starts with a symmetrical key, and only feeds in an abc-symmetrical messages, then the hash function will effectively have only 512 bits of state, and will remain in the symmetrical subspace during message absorption. However right before the finalization rounds the message length is absorbed, and the message length block cannot reasonably be constrained to be positive and abc-symmetrical. Therefore this observation has limited direct effects (we will see some indirect effects later).
However, if the message length is zero then the absorbed message length block will consist of all zeros, and will be abc-symmetrical! We can see this effect in practice: The hash of the zero-length message under a symmetrical key (reminder: one consisting of eight 64-bit words, repeated twice each) will itself be symmetrical, and thus only have 64 bits of entropy:
# The resultant hash is "779e443a6d7a63df" repeated twice.
MeowHash("ABCDEFGH" * 16, "") == hex_to_bytes("779e443a6d7a63df779e443a6d7a63df")Recall from before when the message is not a multiple of 256 bytes in length that Meow hash actually absorbs some message blocks after absorbing the message length block. We can exploit this out-of-sequence order to construct a special key that symmetrizes the state after the asymmetrical length field is already incorporated, but before any message bytes are incorporated. Specifically, for any message length less than 256 that’s a multiple of 32 we can construct a key that will reach a symmetrized state after the length is absorbed by simply running Meow hash’s absorption function backwards (see the above invertibility). Such a key will make it so that any abc-symmetrical message of the given length gets sent to a symmetrical 64-bit hash.
For example, one such key for messages of length 32 is:
symmetrize32 = hex_to_bytes(
"aa694fb61039bf2c7e2d743dc1bb2e19a97070a970f2a9c1a9700172f20195a9"
"2000000000000000000000000000000000000000000000000000000000000000"
"63e4e370970793d3ac543500ba51dc9d09636363636363d06363b76363b76363"
"0000000000000000000000000000000000000000000000000000000000000000"
)After the length is absorbed under this key (for a 32-byte message) the hash function internal state will be all zeros, and as a consequence any abc-symmetrical 32-byte message hashed under this key will result in a symmetrical 64-bit hash. For example:
# The resultant hash is "6a13b8886b91cf29" repeated twice.
MeowHash(symmetrize32, "abcdefghabcdefghaijklmnhaijklmnh") == hex_to_bytes("6a13b8886b91cf296a13b8886b91cf29")One naive fix would be to break symmetry by reducing the key size, and instead initialize some of the lanes with asymmetric constants. We will see later in the SAT-based attacks section that this doesn’t completely resolve the issue, and the mere existence of this symmetric invariant subspace will be a useful foothold.
Collisions via symmetry
TL;DR: No invalidation, low heebie-jeebies. Symmetry reduces the entropy of certain very specific hashes down to 64 bits, which we can exploit to generate collisions for the same key. The impact is low in practice, because it requires a carefully crafted weak key, and carefully crafted messages.
Let us examine the function:
def f(x: uint64) -> uint64:
message = four copies of x, forming a 32-byte block
h = MeowHash(symmetrize32, message)
# Note that h's low order and high order 64 bits are equal.
return the low order 64-bits of hIf we could find x and y with f(x) = f(y) then that would give us a pair of messages that hash (under symmetrize32 as the key) to the same value.
But f’s output only has 64 bits of entropy, so we can find a collision in f by the birthday bound with ≈2³² invocations, for example with a variant of the tortoise and hare algorithm2:
// Put this in the same directory as the meow_hash_x64_aesni.h file from the Meow hash repo,
// then compile with: gcc -O3 -march=native tortoise_hare.c -o tortoise_hare
#include <stdint.h>
#include <stdio.h>
#include "meow_hash_x64_aesni.h"
uint64_t f(uint64_t x) {
uint64_t symmetrize32[16] = {
3224358602161482154llu, 1814594138510994814llu, 13954951486077169833llu, 12219675304746119337llu,
32, 0, 0, 0,
15245537510594700387llu, 11375056618140292268llu, 15015954861103735561llu, 7161769469951828835llu,
0, 0, 0, 0
};
uint64_t message[4] = {x, x, x, x};
meow_u128 h = MeowHash(symmetrize32, 32, message);
return *(uint64_t*) &h;
}
void print_num(uint64_t x) {
uint8_t* byte_ptr = &x;
for (int i = 0; i < 8; i++)
printf("%02x", byte_ptr[i]);
printf("\n");
}
int main() {
uint64_t tortoise = 0;
uint64_t hare = 0;
do {
tortoise = f(tortoise);
hare = f(f(hare));
} while (tortoise != hare);
printf("Cycle detected! Hare location: "); print_num(hare);
uint64_t x1, x2;
tortoise = 0;
while (tortoise != hare) {
x1 = tortoise;
x2 = hare;
tortoise = f(tortoise);
hare = f(hare);
}
printf("Collision:\n");
print_num(x1);
print_num(x2);
}The above program will run for ≈10 minutes, invoke Meow hash 32,872,851,446 times, and output:
Cycle detected! Hare location: 5272676d299ebafc
Collision:
c78c1c8595b8a251
6a2875bcab55af2a
corresponding to the claim that the messages:
c78c1c8595b8a251c78c1c8595b8a251c78c1c8595b8a251c78c1c8595b8a251
and
6a2875bcab55af2a6a2875bcab55af2a6a2875bcab55af2a6a2875bcab55af2a
collide under the key symmetrize32 given above.
In particular, both messages hash to the symmetrical value 04b12caaebcaf6ae04b12caaebcaf6ae.
Note that unlike with the preimages and collisions we were computing before by running Meow hash backwards, these collisions occur under one key.
Changing Meow hash to absorb the message in the obvious order (i.e. every message byte in order, then the message length at the end) would prevent this attack from generating collisions under the same key, however a variant of the above program would still be able to find these symmetrical collisions between different keys of hashes of the empty string. Again, naively, one could attempt to fix all of these symmetry issues by reducing the key size and initializing some lanes with asymmetric constants. We will see later in the SAT-solving section that this is actually insufficient, and a variant of the above program could be constructed to find collisions anyway, albeit of more contrived messages.
Differential cryptanalysis
As a brief refresher, the core idea of differential cryptanalysis is to take a function \(f : \{0, 1\}^m \to \{0, 1\}^n\), and find some \(\Delta : \{0, 1\}^m\) and \(\Delta' : \{0, 1\}^n\) such that for some fraction of inputs \(x\), the relation \(f(x) \oplus f(x \oplus \Delta) = \Delta'\) holds. Such a pair is called a differential characteristic, and the fraction of \(x\) for which the relation holds is the probability of the characteristic. If \(f\) is a large random function then \(f_\Delta(x) = f(x) \oplus f(x \oplus \Delta)\) should also be almost3 a random function for \(\Delta \ne 0\), and therefore \(f_\Delta\) should only output \(\Delta'\) approximately \(2^{-n}\) of the time. By contraposition, if one can find a high probability differential characteristic then one has established that \(f\) doesn’t look random.
In general one might ask about a relaxation of the \(f(x) \oplus f(x \oplus \Delta) = \Delta'\) constraint, and merely assert that \(f_\Delta\) satisfies any other predicate more/less often than a random function should — this general family of attacks is known as truncated differential cryptanalysis.
The AES decryption round function is highly diffusive (the mix columns operation is a dense 32x32 matrix multiplication over GF(2)), and contains degree 7 non-linear terms via the 8-bit sbox. Between these two, AES is relatively secure against differential cryptanalysis, and Meow hash inherits this security whenever bits receive enough AES rounds. However, as we will see in later sections, Meow hash applies too few rounds of AES to be completely resistant.
Interactive demo — click on the blue boxes below to design your own differential characteristic!
Commonly one will attempt to cancel differences injected into the state in one part of \(\Delta\) with additional differences elsewhere in \(\Delta\). To get a sense of how this goes, below I have an interactive diagram of Meow hash absorbing 384 bytes of message4, as twelve 32-byte blocks. One can click on any message byte to toggle injecting a difference on that byte (that is, you are designing \(\Delta\), and the diagram renders the resulting \(\Delta'\)).
In the below diagram a black wire indicates no difference, a red wire indicates a known difference, and a yellow wire indicates an unknown difference. Observe that the non-linearity of AES’s sbox promotes a known difference (red) to an unknown difference (yellow) which cannot be corrected with probability 1; such an sbox whose input has a delta is known as active.
When one known difference (red) interacts with another via xor or addition, we model them as canceling (even though this isn’t totally sound5). This is your main tool for controlling the spread of differences.
Additionally, one may simply guess the values of unknown differences in active AES sboxes, in order to prevent red wires from being promoted to yellow wires. However, this comes at the cost of reducing the probability of the characteristic holding (because we must correctly guess these unknown values). To enable this, simply click on one of the dark gray AES rounds to indicate that you’d like to guess all of the deltas generated in its sboxes; the AES round will turn pink. This requires guessing the deltas generated in each active sbox, and therefore will effectively multiply the probability of your characteristic by \(2^{-7 n}\) where \(n\) is the number of red or yellow wires going into the AES round6.
Opportunities to cancel out internal differences with new differences are shown as dark teal bytes in the message. The first and last byte of each 32-byte block are only injected in one place, and are therefore a prime target for attack — these bytes are shown with a green border. Likewise, the middle two bytes in each 32-byte block are injected in three places, making them trickier to use, and are shown with a red border.
Vanishing differential characteristics
TL;DR: High invalidation, high heebie-jeebies. Meow hash’s absorption function exhibits a vanishing differential characteristic that holds with probability \(\approx 2^{-45}\). This alone breaks the level 3 and level 2 security notions.
One particularly devastating form of differential characteristic is a vanishing one, where \(\Delta' = 0\). A vanishing characteristic on the absorption function of Meow hash immediately allows the construction of collisions, as \(f(x) \oplus f(x \oplus \Delta) = 0\) is equivalent to saying that the messages \(x\) and \(x \oplus \Delta\) collide the internal state, and thus the final hash value. We now attempt to construct a vanishing characteristic in Meow hash’s absorption function.
Our most critical tool for this is guessing. As one plays with the above interactive diagram one quickly realizes that making all the differences cancel out internally seems pretty hopeless, because the moment a red difference enters AES it turns into a yellow unknown difference, which can never be canceled. However, we may simply guess the difference on any yellow wire to effectively convert it into a red wire. Of course, making these guesses imposes a cost: the probability that our characteristic holds goes down commensurately.
Puzzle: If you’d like a challenge, you can try to find a vanishing characteristic in Meow hash (thus breaking it!) yourself using the above interactive diagram. That is, pick some message bytes to set deltas on (click on the blue boxes), and some AES rounds to guess the deltas in (click on dark grey boxes) such that all the differences cancel out internally, and all the output wires are black. Hint: The minimum solution will involve setting deltas on 15 message bytes, and setting 3 AES rounds to guess mode.
Spoiler alert: If you don’t mind spoilers, you can press this button to load the vanishing characteristic into the above interactive diagram now:
We can also model this attack as a SAT instance, and automatically search for a vanishing characteristic (which is how I found one in the first place):
import autosat
import numpy as np
# This is the number of 256-byte blocks of message absorption to model.
BLOCK_COUNT = 2
MAX_DELTA_BYTES = 15
MAX_GUESSES = 3
@autosat.sat
def xor_bytes(a_delta, a_unknown, b_delta, b_unknown):
# If either byte has an unknown delta, then the result is unknown.
if a_unknown or b_unknown:
return 0, 1
# Otherwise, let the known deltas cancel if they're both present.
# This isn't totally sound — the deltas might be known and necessarily unequal.
return a_delta ^ b_delta, 0
@autosat.sat
def aes_sbox(a_delta, a_unknown, spend_guess):
if a_delta or a_unknown:
# One may spend a guess point to learn the output delta.
if spend_guess:
return 1, 0
return 0, 1
return 0, 0
class Byte:
def __init__(self, variables):
self.variables = variables
self.delta, self.unknown = variables
# These bits are mutually exclusive — we want to implement a trit.
inst.add_clause(~self.delta, ~self.unknown)
def force_no_difference(self):
self.delta.make_equal(False)
self.unknown.make_equal(False)
def xor(self, other: "Byte") -> "Byte":
return Byte(xor_bytes(*self.variables + other.variables))
inst = autosat.Instance()
message_inject_vars = inst.new_vars(256 * BLOCK_COUNT)
message_inject_bytes = [Byte([var, inst.get_constant(False)]) for var in message_inject_vars]
lanes = [[Byte(inst.new_vars(2)) for _ in range(16)] for _ in range(8)]
spend_names = {}
def make_spend(spend_on):
var = inst.new_var()
spend_names[var] = spend_on
return var
def xor_lanes(dest_lane: int, source_lane: int):
lanes[dest_lane] = [a.xor(b) for a, b in zip(lanes[dest_lane], lanes[source_lane])]
def xor_in_message(dest_lane: int, addr: int):
lanes[dest_lane] = [a.xor(b) for a, b in zip(lanes[dest_lane], message_inject_bytes[addr : addr + 16])]
def aesdec(dest_lane: int, source_lane: int):
lane = lanes[dest_lane]
# 1. Shift rows.
for row_index in range(4):
row = lane[row_index::4]
for _ in range(row_index):
row = row[-1:] + row[:-1]
lane[row_index::4] = row
# 2. Inverse sbox.
lane[:] = [
Byte(aes_sbox(
byte.delta, byte.unknown,
make_spend("aes_round=%i_lane=%i" % (round_number, dest_lane)),
))
for byte in lane
]
# 3. Inverse mix columns
for column_index in range(4):
column = lane[column_index*4 : column_index*4 + 4]
result = column[0].xor(column[1]).xor(column[2].xor(column[3]))
lane[column_index*4 : column_index*4 + 4] = 4 * [result]
# 4. Add round key
xor_lanes(dest_lane, source_lane)
def meow_mix(r1, r2, r3, r4, r5, address):
aesdec(r1, r2)
xor_in_message(r3, address + 0x0f) # Actually an add — this introduces some unsoundness.
xor_in_message(r2, address + 0x00)
aesdec(r2, r4)
xor_in_message(r5, address + 0x01) # Actually an add — this introduces some unsoundness.
xor_in_message(r4, address + 0x10)
# Demand at least one delta be injected in the first 32-byte block, to rule out the trivial solution.
inst.add_clause(*message_inject_vars[:32])
# We start out in the all no differences state.
for lane in lanes:
for byte in lane:
byte.force_no_difference()
# Model message absorption.
for round_number in range(8 * BLOCK_COUNT):
lanes = (round_number + np.array([0, 4, 6, 1, 2])) % 8
meow_mix(*lanes, 0x20 * round_number)
# Demand that we end in the no differences state — thus a vanishing characteristic.
for lane in lanes:
for byte in lane:
byte.force_no_difference()
# Constrain the number of deltas injected and guesses used.
autosat.cardinality_constraint(message_inject_vars, at_most=MAX_DELTA_BYTES)
autosat.cardinality_constraint(list(spend_names.keys()), at_most=MAX_GUESSES)
solution = inst.solve()
for byte_index, var in enumerate(message_inject_vars):
if var.decode(solution):
print("Injected difference:", byte_index)
for var, name in spend_names.items():
if var.decode(solution):
print("Guess:", name)This program outputs:
Injected difference: 31
Injected difference: 159
Injected difference: 168
Injected difference: 169
Injected difference: 170
Injected difference: 171
Injected difference: 215
Injected difference: 216
Injected difference: 217
Injected difference: 218
Injected difference: 255
Injected difference: 264
Injected difference: 265
Injected difference: 266
Injected difference: 267
Guess: aes_round=1_lane=1
Guess: aes_round=5_lane=5
Guess: aes_round=8_lane=0
Here is a screenshot of entering this characteristic into the interactive diagram:
Our SAT solving approach isn’t totally sound (it can report a characteristic that doesn’t work for various reasons), and nor is the interactive diagram sound, but all the fiddly details in this characteristic thankfully do work out. In order for this characteristic to hold we must guess the deltas generated in three AES sboxes, which holds \(2^{-7 \cdot 3} = 2^{-21}\) of the time. Additionally, we incorporate message deltas via additions in three places, which requires us to get lucky with the carries in the additions. In this characteristic we have choice of what delta we inject into the three green-bordered bytes, which in turn determines what deltas we must cancel out with the other twelve bytes, which are incorporated via addition. By optimizing the former values to minimize the Hamming weight of the latter values, we can require that we get lucky with only 27 carries, which holds \(2^{-27}\) of the time.
Therefore, overall this characteristic should hold with probability \(2^{-21} \cdot 2^{-27} = 2^{-48}\). However, via empirical searching I have found that this characteristic actually seems to hold slightly more often — around \(2^{-45}\) of the time — for reasons I don’t really understand.
To be very concrete, the claim is that running the following function on any 32-byte aligned pointer into a message7 will leave its hash unchanged with probability \(2^{-45}\) for a random key:
#define DELTA 0x1d
#define DELTA_PRIME 0x09838680
void apply_vanishing_characteristic(uint8_t* msg) {
msg[ 31] ^= DELTA;
msg[159] ^= DELTA;
msg[255] ^= DELTA;
// Our characteristic also requires that these four message bytes not generate any carries.
assert((*(uint32_t*) (msg + 119)) == 0);
*(uint32_t*) (msg + 168) ^= DELTA_PRIME;
*(uint32_t*) (msg + 215) ^= DELTA_PRIME;
*(uint32_t*) (msg + 264) ^= DELTA_PRIME;
}To give an even more concrete example, the message of 512 null bytes and the following message will collide with probability \(\approx 2^{-45}\) under a random key:
000000000000000000000000000000000000000000000000000000000000001d0000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000001d0000000000000000808683090000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000808683090000000000000000000000000000000000000000000000000000000000000000000000001d
00000000000000008086830900000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
For example, by random sampling8 I found the following key under which they collide:
e12ef6bba5ddf9ece38552a2a8a65eb5307652ad25ce22f01eba21151f4e9500a0b429edc3ed05ead9c2bca3812aefc8b4fe430b0fdc8123a5e29b88adc4ca21
a5cdcff233b57bf404ec70ad2eaccde07dcce23cd159fa717ce1d7f3d94ba11016ed203a8ec4717bf45160bdff68847404df3ae88c08b4aeb95c71c70cd77319
Further, by randomizing part of the message we can get multiple shots on any one key. For example, under the default key the following two messages collide:
d651769417c41a2d24cbeb8c5ea81f0000222aadc5716793a7533b103bc33fc81577b700cd8e001b7f00101900b3314a123e6bdf1b2d6a4c6232ca637c0343fe
8b647083ba75c12eabda55d67e2eb88a6a47a1bb11906d853fdb2c79c9523f5bfe0dff28bdadb902922f3d79b9492a0000c224334dfd3000000000edbc2f5293
000000000000000000000000000000000000000000000000000000000000003f0000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
and
d651769417c41a2d24cbeb8c5ea81f0000222aadc5716793a7533b103bc33fd51577b700cd8e001b7f00101900b3314a123e6bdf1b2d6a4c6232ca637c0343fe
8b647083ba75c12eabda55d67e2eb88a6a47a1bb11906d853fdb2c79c9523f5bfe0dff28bdadb902922f3d79b9492a0000c224334dfd3000000000edbc2f5293
00000000000000000000000000000000000000000000000000000000000000220000000000000000808683090000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000808683090000000000000000000000000000000000000000000000000000000000000000000000001d
00000000000000008086830900000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Where the second message here is simply the first with apply_vanishing_characteristic applied.
Key recovery
TL;DR: High invalidation, very high heebie-jeebies. An attacker who can merely query if the lowest order bit of the hashes of two messages collide can recover the complete 1024-bit key using \(\approx 2^{49}\) queries. This provides a key recovery attack against even remote hash tables where we never directly see any hash output.
Let us define a key recovery game, parameterized by a number of bits \(\lambda\):
- The victim generates a random 1024-bit key
k. - The attacker makes a series of (possibly adaptive) queries of the victim, where each query consists of:
- The attacker sends the victim a pair of messages
aandb. - The victim informs the attacker if
MeowHash(k, a)andMeowHash(k, b)collide in their bottom \(\lambda\) bits, but not what those bits are. The attacker learns nothing else about the hashes.
- The attacker sends the victim a pair of messages
- The attacker must correctly guess the victim’s key.
This key recovery game might correspond to a threat model where the victim is a long running web server, with the attack looking like:
- The attacker sends a request to the web server, which creates a hash table using Meow hash for servicing the request using a global key that was chosen at start up.
- The attacker’s request somehow contains two strings that the web server inserts into the hash table (perhaps the web framework inserts all of the request’s URL parameters into the hash table or something).
- Based on timing the attacker can tell if there was a collision. However, the hash table defaults to having 16 slots, so the attacker only learns if the bottom \(\lambda = 4\) bits of the two messages collide.
We will show that even in this incredibly constrained attack scenario where the attacker never gets to directly see any hash output whatsoever, they will be able to recover the complete 1024-bit Meow hash key using \(\approx 2^{49}\) queries for any positive \(\lambda\), even \(\lambda = 1\). (That is, even if they only learn if the bottom bit of the hashes collide!)
We will do this in three stages, first showing an attack allowing recovery of 8 bits of the key in the \(\lambda = 128\) setting, then we will show how to extend this to the \(\lambda = 1\) setting, and finally we will show how to extend this using SAT solving to full key recovery.
Partial key recovery
Our vanishing characteristic will only hold if our guesses as to the values being fed into the AES sboxes were correct.
Therefore, if we find a message m such that MeowHash(k, m) == MeowHash(k, m') where m' is m but with the vanishing characteristic applied, then we learn the values being fed into the three active AES sboxes in our characteristic (assuming that this wasn’t a “natural” collision by random happenstance — but those only occur with \(2^{-128}\) probability, so can be neglected).
We can find such a message pair by random chance by simply by making \(\approx 2^{45}\) queries on average in the \(\lambda = 128\) setting. For subtle reasons, we actually only learn the values being fed into the active sboxes to within one of two values (because if \(\text{sbox}[x] \oplus \text{sbox}[x \oplus \Delta] = \Delta'\) holds for \(x = a\), then it will also hold for \(x = a \oplus \Delta\)). However, we can simply run the attack twice for two different values of \(\Delta\), to disambiguate. The second invocation takes something like \(2^{30}\) additional queries, because we already know the three sbox bytes to within two possibilities, and therefore can narrow our search enormously.
From looking at the above screenshot one will note that the leftmost sbox whose value we learn (namely the top byte of lane 1) corresponds to byte 31 in the secret key. Therefore, this allows us to recover 8 bits of the key with \(\approx 2^{45}\) queries on average.
Here is a proof of concept implementation of this attack, without the disambiguation step (you’d need to run the attack again with a different valid DELTA and DELTA_PRIME pair):
// Compile with: gcc -O3 -march=native partial_key_recovery.c -o partial_key_recovery
#include <stdint.h>
#include <stdio.h>
#include "meow_hash_x64_aesni.h"
#define DELTA 0x1d
#define DELTA_PRIME 0x09838680
// We need a PRNG to randomize bits of the message to get multiple chances at success.
static uint64_t gen_pseudorand(uint64_t use, uint64_t trial, uint64_t worker_number) {
__m128i state = _mm_set_epi64x(use, 0x12345678);
__m128i key = _mm_set_epi64x(trial, worker_number);
for (int i = 0; i < 4; i++)
state = _mm_aesdec_si128(state, key);
return _mm_cvtsi128_si64(state);
}
static void print_num(int length, uint8_t* data) {
for (int i = 0; i < length; i++)
printf("%02x", data[i]);
printf("\n");
}
void apply_vanishing_characteristic(uint8_t* msg) {
msg[ 31] ^= DELTA;
msg[159] ^= DELTA;
msg[255] ^= DELTA;
assert((*(uint32_t*) (msg + 119)) == 0);
*((uint32_t*) (msg + 168)) ^= DELTA_PRIME;
*((uint32_t*) (msg + 215)) ^= DELTA_PRIME;
*((uint32_t*) (msg + 264)) ^= DELTA_PRIME;
}
int main(int argc, char** argv) {
if (argc != 3) {
printf("Usage: partial_key_recovery secret_key_index worker_number\n");
return 1;
}
uint64_t secret_key_index = atoi(argv[1]);
uint64_t worker_number = atoi(argv[2]);
// Generate a random secret key -- our only interface to this key will be hashing under it.
uint8_t secret_key[128];
for (int i = 0; i < 16; i++)
((uint64_t*) secret_key)[i] = gen_pseudorand(1, i, secret_key_index);
printf("Secret key: "); print_num(128, secret_key);
printf("The search should return either: 0x%02x or 0x%02x\n", secret_key[31], secret_key[31] ^ DELTA);
fflush(stdout); // Flush so GNU parallel will print the above messages immediately.
uint8_t deduplicated_guess_bytes[128];
int index = 0;
for (int b = 0; b < 256; b++) {
for (int i = 0; i < index; i++)
if (deduplicated_guess_bytes[i] == b ^ DELTA)
goto skip;
deduplicated_guess_bytes[index++] = b;
skip:;
}
uint8_t message[512] = {0};
for (uint64_t trial = 0; ; trial++) {
*((uint64_t*) message) = gen_pseudorand(0, trial, worker_number);
// We need to randomize over the inputs to the other two sboxes to get multiple chances.
message[159] = message[0];
message[255] = message[1];
for (int guess_byte_index = 0; guess_byte_index < 128; guess_byte_index++) {
int guess_byte = deduplicated_guess_bytes[guess_byte_index];
message[31] = guess_byte;
meow_u128 h1 = MeowHash(secret_key, 512, message);
apply_vanishing_characteristic(message);
meow_u128 h2 = MeowHash(secret_key, 512, message);
apply_vanishing_characteristic(message);
if (_mm_test_all_ones(_mm_cmpeq_epi8(h1, h2))) {
printf("Collision: guess_byte=0x%02x trial=%lu worker_number=%lu\n", guess_byte, trial, worker_number);
printf("Input message: "); print_num(512, message);
printf("\n\nWe have learned that either secret_key[31] == 0x%02x or secret_key[31] == 0x%02x\n\n",
guess_byte, guess_byte ^ DELTA);
return 0;
}
}
}
}The above code takes quite a lot of time to run (it took approximately a day on a Ryzen 9 3900X parallelized on all cores), so I recommend parallelizing like:
parallel -u ./partial_key_recovery 0 ::: {1..$NUMBER_OF_THREADS}
This attack as described only works in the \(\lambda = 128\) setting, where our query returns if the full hashes collide.
This is unrealistic against a remote hash table, which will typically only be using the bottom few bits of the hash.
However, we can promote to the \(\lambda = 1\) setting by observing that the collisions we’re generating are full collisions of the internal state — therefore to test if a and b collide it suffices to check if MeowHash(k, a || suffix) & 1 == MeowHash(k, b || suffix) & 1 for many suffixes.
If a and b don’t collide it will take 2 queries on average (\(1 + \frac12 + \frac14 + \cdots\)) to determine this.
When a and b do collide we can reach near certainty of this after a hundred queries.
Our partial key recovery attack only needs to find two collisions, so the former doubling dominates, and pushes our attack up to \(\approx 2^{46}\) queries on average to recover 8 bits of key in the \(\lambda = 1\) setting.
Full key recovery
Now that we can recover some state bytes in the \(\lambda = 1\) setting, we will show how to recover the entire state and thus entire key.
Before we begin, I would like to encourage the reader to only lightly skim the text that follows up until the query complexity section. The full key recovery attack is full of fiddly boring minutiae that are not particularly enlightening. The main moral I would like the reader to take away is that partial state recovery will nearly inevitably turn into full state recovery in a design like Meow hash.
With that in mind, let us diagram the bytes of internal state we plan to recover in a single lane, with the bytes we intend to recover labeled in green:

Our attack will recover the state bytes in four phases, labeled 1 through 4 in the above diagram. Our partial key recovery attack from above allows us to recover the single green state byte of phase one — we will call this byte the indicator byte. We will now treat recovering the internal state byte of phase 1 as a subroutine — we will call recovering this byte reading the indicator.
Examine the top green byte of the seven green bytes of phase 2. Note that the operation at phase 2 is a pair of 64-bit additions of message bytes into the lane. If, hypothetically, this top byte’s top bit is set then setting the corresponding message byte to 0x80 would cause a carry, which would change the indicator byte. Therefore, we can determine if the top bit in the top byte of the green bytes of phase 2 is set by reading the indicator with a message that uses 0x80 in the appropriate position.
Once the top bit of the top green byte in phase 2 is known, observe that we can now read the second to top bit of the top byte, by adding an appropriate value that will cause a carry into the indicator byte only if the second to top bit is set. In this fashion with 56 reads of the indicator byte with carefully crafted messages we can recover all of the green bytes of phase 2.
To recover the four phase 3 bytes, observe that those four byte positions are the ones that affect the indicator byte through AES. Therefore, we can simply probe the four bytes one at a time, by injecting two differences into each, and observing the changes in the indicator byte. How these two differences affect the indicator byte will always suffice to infer the underlying byte, because the pair \(\text{sbox}[x] \oplus \text{sbox}[x \oplus \text{0x01}]\) and \(\text{sbox}[x] \oplus \text{sbox}[x \oplus \text{0x02}]\) always uniquely determines \(x\).
To accomplish phase 4 recovery we can proceed much like in phase 2, and recover one bit at a time by probing for when carries in the phase 4 bytes spill over into the phase 3 bytes, which in turn would affect the indicator byte.
At this point I would like to paint a picture of how clear it should be that we will be able to recover almost the entire internal state. We can inject differences into the state at various points that non-linearly interact with unknown bits — whenever this non-linear interaction has an easily characterizable path to affect the indicator byte we will probably be able to recover said unknown bits.
To make things even more clear, I’ve been repeatedly using reading the indicator as a subroutine, but that is merely for efficiency. One could also consider reading the phase 2 bytes as a subroutine, or the phase 3 ones, and so on. If ever you can inject a message difference that will interact non-linearly with unknown state to conditionally cause a change in some bytes that you can already recover then you can immediately add this new unknown state to the list of what you can recover. This compounds upon itself extremely quickly, and as a consequence we should expect that recovering essentially the entire state will be possible.
Next, we apply the above four phases of recovery on all eight lanes, by repeating them all eight times, with the offset into the message at which we apply the attack shifted by 32 bytes each time. In this way we recover all of the highlit green bytes from the above diagram, but in all eight lanes.
For those who are interested, the appendix contains example code that treats reading the indicator as a subroutine, and performs these four phases of recovery in all eight lanes. The code is uninteresting — the trickiness mostly consists of getting all the annoying details right.
Finally, having recovered this set of internal bytes we may simply SAT solve for the initial key. To validate that this attack works, the aforementioned code in the appendix runs this recovery attack (again, treating reading the indicator byte as a subroutine — it cheats and uses the secret key to do this, but this is its only interaction with the secret key), and emits a list of recovered internal state bytes. I have a separate script (unpublished right now) that models Meow hash’s evaluation to the bit level in SAT, which these recovered bytes can be incorporated into as SAT constraints. Given these constraints the SAT solver emits the secret key with a few minutes of solving.
Query complexity
Our full key recovery attack on one lane makes 1 call to the “read the indicator” subroutine in phase 1, 56 calls in phase 2, 8 calls in phase 3, and 64 calls in phase 4. We repeat this attack on all eight lanes, for a total of 1,032 calls. Recall that each read of the indicator consists of performing our previous partial key recovery attack, which requires \(\approx 2^{46}\) hash queries on average.
Therefore, it seems naively like our attack requires \(\approx 2^{56}\) hash queries on average to recover the full 1024-bit key in the \(\lambda = 1\) setting. However, once we find our first message pair that satisfies the vanishing characteristic in each lane we learn the bytes required in other lanes to make the characteristic hold. While various message modifications shown above to perform phases 1 through 4 will disrupt these other bytes somewhat, they never disrupt them enough to not allow us to reuse most of the searching work.
The consequence of this is that (if carefully implemented) the true cost of this full key recovery attack is only negligibly more than the cost of running the partial key recovery attack in all eight lanes, namely \(8 \cdot 2^{46} = 2^{49}\) queries in the \(\lambda = 1\) setting.
SAT-based attacks
TL;DR: No invalidation, high heebie-jeebies. Meow hash is highly susceptible to SAT solving in the known key setting. This gives us powerful attacks that would be considered complete breaks for a cryptographic hash function (mind you, which Meow hash is not claiming to be). Nonetheless, the success of SAT solving paints a picture of a hash function with insufficient mixing.
As discussed previously, Meow hash incorporates an enormous number of message bits per AES round, giving an attacker an enormous number of degrees of freedom to twiddle to attempt an attack. However, exploiting all of these degrees of freedom is quite difficult by hand, as one must control a rapidly diverging cascade of effects. But SAT solvers excel at such problems.
The first step is to encode Meow hash as a SAT instance. To do this I used a personal library for converting lookup tables into CNF clauses, along with CNF implementations of things like addition (published here). Using this library I encoded the AES round function and the rest of Meow hash into SAT instances, which I attacked using CryptoMiniSat 5.
We will discuss several capabilities that this gives us. Everything that follows assumes we know the key (perhaps we have already recovered it using the attacks of the previous section).
Preimage given partial control over the key
As discussed in the invertibility section, for any message m and any desired hash h, one can compute a key k such that MeowHash(k, m) == h simply by running Meow hash backwards.
In particular, this allows us to compute preimages of any hashes we want, so long as we don’t care what key the preimage is under.
This isn’t a problem per se, but if the Meow hash folks wanted to fix it they might be tempted to reduce the key to something like 512 bits, and fix the remaining initial state in Meow hash to some constants.
For a generic secure sponge construction this would be sufficient, but it turns out to be insufficient for Meow hash — given control over even just 128 bits of the key along with the message SAT solving can perform a preimage attack.
That is, for any desired hash h and 768-bit key prefix kp, we can construct a message m and 256-bit key suffix ks such that MeowHash(kp || ks, m) == h.
Therefore, fixing even most of the initial state is insufficient to prevent preimage attacks under a chosen key.
Near preimage without control over the key
Meow hash’s internal state is quite steerable via SAT solving. For example, let’s say that we wish to zero out seven of the eight lanes starting from the default key. We can construct a SAT instance that requests this, and CryptoMiniSat takes three minutes to find the 256-byte message:
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
1a01b6c5ec67ee7b52f0097edcf1f9d2125098afd312f69b1a3044d58bfa32d9bde40a394fe2484eb5b5f310f1f8b136a824cf0aaf9d0f2187f3977a9b4d39fd
a597e9162735cd0a845a335e725ba78dfffe5ac6673770d7520ee5506bf3704a154f06a67e1e6c241a46ac3f85bd94650746dd7e3eba4d22378aba22fb63e2bb
749e4988d8575196304e7a883081ed07c8abea425222ce24447bbe6a71e43276012eb9f1819f4e40b71fb47cabff921c856381a3a7e997377fbcc2990f80aaa7
After absorbing this message starting from the default key Meow hash’s internal state will be:
lane0 = 00000000000000000000000000000000
lane1 = 00000000000000000000000000000000
lane2 = 00000000000000000000000000000000
lane3 = 00000000000000000000000000000000
lane4 = 00000000000000000000000000000000
lane5 = 00000000000000000000000000000000
lane6 = 00000000000000000000000000000000
lane7 = 268a543b855f8ee0f9861ce63910ca36
As you can see, controlling nearly the entire internal state is readily possible. I think it is plausible that cleverer SAT techniques would allow complete control over the state, and thus preimage attacks.
Symmetrization
As noted before, Meow hash’s absorption function has a 512-bit invariant subspace where each lane’s low and high 64-bit words are equal. As discussed before, a key that starts in this subspace is weak, in that the hashes of abc-symmetrical messages will be symmetrical, and thus only have 64 bits of entropy. However, if we start from a state outside of this subspace, can we drive Meow hash into it?
The answer turns out to be yes, using SAT solving. With eight minutes of solving time CryptoMiniSat finds the following 256-byte message:
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
34e8fbb91549919f03bf17332b38db0e0701dcf77891a786cfb48bad8692250fe4f2fc7479771d6590c45be95140ef30a9d3e71b025b34ba3de979e761417f44
b1a95334c943228ce4d5486edd87e371f1ddce399b28d135af0833f2615b346fd647600ff31509b50439c5c39d7422a471ad616f28f4f3a18a91abf5557e149c
After absorbing this message starting from the default key Meow hash’s internal state will be (spaces added to highlight symmetry):
lane0 = c3404d53c89f8768 c3404d53c89f8768
lane1 = 3055fa02e6af1388 3055fa02e6af1388
lane2 = ad76116f5bafd3df ad76116f5bafd3df
lane3 = 4e85036e0acd1ad3 4e85036e0acd1ad3
lane4 = db5be3e1f4172f1b db5be3e1f4172f1b
lane5 = e6bbe1a430518193 e6bbe1a430518193
lane6 = 7de62fe9179e3893 7de62fe9179e3893
lane7 = c23151175c952785 c23151175c952785
Therefore, fixing even the entire initial state to be asymmetrical is insufficient to prevent Meow hash from being driven into the symmetrical invariant subspace. Symmetrization will prove to be a valuable tool for our next attack, which will be more efficient inside the invariant subspace.
Collisions between messages of the same length
Given a SAT implementation of Meow hash it is tempting to just directly request collisions in the internal state using our SAT solver. I couldn’t find a way to make this work. Solving would stall out when I asked for partial collisions of more than 950ish bits of the internal state. If I modeled the finalization rounds and requested a partial collision in the final hash solving completely ground to a halt due to the complexity of said finalization.
However, I did ultimately find a solution: Solving for a collision inside of the 512-bit invariant symmetrical subspace does work. The core observation is that once in the invariant subspace one may dramatically simplify the SAT instance, by omitting half of the circuitry, at the cost of requiring that the message be abc-symmetrical. Despite the solver only having 43.75% as many message bits to manipulate, the simpler 512-bit problem seems to be much more tractable9.
This leads to the following attack to produce a collision between two messages of the same length:
- For each of the two messages, SAT solve for a block to append to drive the state into the 512-bit symmetrical subspace. This takes about 10 minutes of solving per message.
- Once in the subspace, SAT solve for a pair of message blocks to append to cause a collision. This seems to take between 5 to 10 hours of solving with appropriate parallel search over parameters. (Bad parameters can result in it taking hundreds of hours to solve, and I have no way of predicting what parameters will be good; I simply launch a dozen jobs in parallel with slightly varying parameters.)
The two messages must be of the same length, because otherwise the internal state collision would be broken by the differing length blocks, which are absorbed at the end.
I performed this attack on a pair of PNG files (random assets from a game I’m making):


First, I padded both messages out to a multiple of 256 bytes and also the same length with the string "https://peter.website/meow-hash-cryptanalysis " repeated as many times as necessary.
Then I ran the above attack (solved for 256-byte blocks to symmetrize each, then solved for 256-byte blocks to make them collide).
These two PNG files collide under the default key (both hash to 14894ed0aaf5f8d225cb65696f8636e9).
Finally, the Meow hash folks provide a utility for checking for collisions in a set of files, and write:
So if you find a collision with Meow128, please report it to us on the GitHub! We may need to look into it in more detail.
So as a minor light-hearted joke I posted an issue on their GitHub reporting these files as colliding, with no additional context, in the hope that they would open up the raw file and find the link to this page.
Cryptanalysis summary
Below is a summary of the above attacks, plus two more from the ancillary section:
| Description | Setting | Invalidation? | Capability |
|---|---|---|---|
| Weak (symmetrical) keys | Chosen key | No | Weak keys exist under which abc-symmetrical messages will get symmetrical 64-bit hashes. |
| Collisions from symmetry | Chosen key | No | We can use the above to generate collisions under a weak key with \(\approx 2^{32}\) work. |
| Vanishing characteristic | Unknown key | Yes | A vanishing characteristic exists with probability \(\approx 2^{-45}\), giving collisions. |
| Key recovery | Unknown key | Yes | We can recover the entire 1024-bit key with \(\approx 2^{49}\) queries. |
| SAT-based collision | Known key | No | SAT solving can find blocks to append to messages of the same length to make them collide. |
| Second-order diff. cryptanalysis | Just finalization rounds | No | Meow hash’s finalization by itself with only 7 out of 12 rounds exhibits bias. |
| Square attack | Unknown key | No | Reduced-round Meow hash with only 5 out of 12 finalization rounds is detectably non-random. |
Let us examine the level 1, 2, and 3 security claims from their taxonomy in more detail:
Level 1 (n bits of output)
A level 1 hash should, given two different inputs, produce a collision with a probability of 1 in \(2^n\). This must hold true even if the inputs differ only by minor differences, such as inserted, deleted, altered or moved sections. It may be possible, with relatively little effort, to intentionally design input that collides. In order to avoid signalling level 2 capabilities, a level 1 hash should not accept a key, seed, nonce or similar.
Level 2 (n bits of output) (k bits of key)
A level 2 hash must take a key as part of the input. In addition to level 1 capabilities a level 2 hash must be designed so that an attacker, given no knowledge of the key or any output from the hash, cannot produce a c-way multicollision with a probability greater than 1 in \(2^{\min(k,n (c-1))}\).
Level 3 (n bits of output) (k bits of key)
In addition to level 2 capabilities, a level 3 hash must be designed so that an attacker with access to compute hashes for arbitrary input, without knowing the key, must not be able to recover the key, or any derivative thereof that is useful for computing hashes, with probability 1 in \(2^p\), using less computations than the equivalent of computing \(2^{k-p}\) hashes. Producing a collision with certainty must be no easier than recovering the key. Generating a c-way multicollision with probability 1 in \(2^q\) must not be possible for \(q<\min(k,n (c-1))\). It must not be possible for an attacker to generate a valid input/hash value pair, without obtaining the key, with probability greater than 1 in \(2^n\).
As you can see, level 1 basically means a checksum, where we protect only against accidental collisions from typical edits, not from intentional collisions. Level 2 makes one security claim, which our vanishing characteristic breaks. Level 3 makes four security claims on top of level 2, where we clearly break the claim that key recovery cannot be done faster than generic, and also that collisions and valid input/hash pairs cannot be made with probability better than generic — of course, none of this is necessary as we already break level 2 security and thus a fortiori level 3.
As a consequence, we break Meow hash down to level 1 (no security) in their taxonomy.
Conclusion
Meow hash has several properties that hinder security, in particular:
- Meow hash absorbs an extremely high number of message bytes per AES round applied. Of course, this was intentional for speed, but it does seem to have affected security greatly.
- The way Meow hash absorbs the message injects the first and last byte of each 32-byte block in just one location each. Every other message byte is injected in at least two places. This is a tremendously valuable tool for attack, and was used in our vanishing characteristic, as well as in our square attack on the finalization rounds.
- Meow hash takes a very long time to chain AES’s output into the next AES’s input. I assume this was to combat the latency of the
aesdecinstruction. However, this severely limits the rate of accumulation of high degree terms. - Meow hash has a symmetry property that results in weak keys, and also enables more control over the internal state in a known-key setting when SAT solving.
Acknowledgements
I would like to thank:
- Shachaf Ben-Kiki, for many discussions, in particular of how to do low-memory birthday bound attacks, and for help figuring out good parameters for SAT solving.
- Max Justicz, for many discussions, especially early on, and also pointing out that Meow hash uses the key for the initial state, and that therefore one can run it backwards to get a key that sends a message to a particular hash. Amusingly, I had been looking at Meow hash for a full day without realizing this.
- Chris McNally, for proofreading help, and for lending me >10k CPU core hours on his server (Christopher Web Services) to perform many of these attacks and searches.
- Adam Suhl, for proofreading help.
- Eran Lambooij, for proofreading help.
- Orr Dunkelman, for suggesting comparing to SHAMATA.
Ancillary attacks and analysis
Above I presented my best attacks. Here I include other analysis, weaker attacks, and some negative results.
Comparison to other AES-based constructions
TL;DR: No invalidation, medium heebie-jeebies. Meow hash uses vastly fewer AES rounds per byte consumed than other AES-based hash functions, including broken ones. Of course, Meow hash is merely targeting MAC security, but it also uses only 25% of the AES rounds of the well-studied AES-based MACs PELICAN and Alpha-MAC. Even for the given number of AES rounds, Meow hash takes a very long time to feed AES’s output back into its input, which severely limits the rate at which high degree terms accumulate.
Before we dive into more detailed statistical analysis, a core question is if Meow hash being secure as a MAC is even plausible. Probably the single most cryptographically concerning property of Meow hash is the enormous ratio of message bits absorbed to AES rounds. Specifically, only 16 AES rounds are applied for every 256 bytes of message absorbed.
Comparison to AES-based hash functions
Compare this to a Davies-Meyer construction or CBC-MAC construction using AES-128, in which 10 AES rounds would be applied per 16 bytes of message. In other words, Meow hash is applying just 10% as many AES rounds per input byte as these generic constructions would.
As another point of comparison, ECHO was a SHA-3 submission that also used the AES round function for all its non-linearity. ECHO-256 was a Merkle-Damgård construction, whose compression function consumed 192 bytes of message to update a 64-byte state. During this compression function the state was expanded to include the message, and thus comprised sixteen 128-bit lanes. ECHO-256 would then apply eight rounds, each consisting of applying two AES rounds to each lane, then linearly mixing each lane with a few other lanes — a somewhat similar structure to Meow hash.
Therefore, ECHO-256 applies 256 AES rounds per 192 bytes of message consumed — Meow hash is applying <5% as many AES rounds per message byte as ECHO-256. A quick glance at the SHA-3 Zoo shows that reduced round ECHO-256 with half the rounds (i.e. still applying 10x the AES per byte as Meow hash!) has borderline-practical published attacks, at least on the compression function.
As yet another point of comparison, SHAMATA was also a SHA-3 submission that used the AES round function for all non-linearity, and has a very similar structure to Meow hash. The message absorption phase of SHAMATA-256 can be described via the following shift-register design:

Specifically, SHAMATA-256 absorbs a series of 16-byte message blocks. For each 16-byte message block apply the following steps:
- Compute
Pby applying AES’s mix-columns on the message block, andQby applying AES’s mix-columns on the transpose of the block. This serves as a linear message expansion. - Let
P₀andP₁be the low and high eight bytes ofP, and likewise forQ. Thus,P₁ || Q₀corresponds to taking half the bytes fromPand half fromQ. Letibe a counter that counts the number of blocks absorbed so far. - For each of the red arrows, xor the indicated value into the register the arrow points at.
- Clock the above shift-register design twice (now ignoring the six red message injection arrows).
We clock the shift-register twice per 16-byte block, and thus SHAMATA-256 applies 2 AES rounds per 16 bytes of message consumed — Meow hash applies half the AES rounds per message byte.
I note some differences that might incline us towards believing that SHAMATA-256 would be stronger than Meow hash:
- SHAMATA-256 applies twice as many AES rounds per message byte absorbed.
- SHAMATA-256 has a much tighter feedback path from AES’s output back into its input, resulting in a high degree being achieved much more rapidly than in Meow hash.
- SHAMATA-256 incorporates the message in way more places, and applies a linear message expansion, making low Hamming weight differentials hard to inject. By comparison, Meow hash incorporates the first and last byte of each 32-byte block in a single place, giving an attacker free rein to inject whatever differentials they want on those bytes. We have exploited this property in our vanishing characteristic.
Collisions can be found in minutes10 in SHAMATA-256, along with relatively high probability differential characteristics.
I should emphasize again that Meow hash’s creators have only targeted security when it’s used as a cryptographic MAC, and were never claiming that Meow hash cannot be distinguished from a random oracle. The Davies-Meyer construction, ECHO, and SHAMATA are all targeting complete ideality as a cryptographic hash, and therefore one would expect that they would require more AES per byte to accomplish this. As an example of this difference, MD5 is notoriously broken wrt collision resistance, and yet no breaks of HMAC-MD5 are known.
Comparison to AES-based MACs
So let’s do a fair apples to apples comparison to AES-based MACs. As a point of comparison, we examine PELICAN, a MAC function designed by Daemen and Rijmen (the creators of AES). Extremely roughly, PELICAN proceeds as follows:
def pelican(key, message):
state = full_10_round_AES(key=key, message=magic_constant)
split the message into 16-byte blocks
for each block:
state ^= block
if not the last block:
state = single_unkeyed_AES_round(state)
state = single_unkeyed_AES_round(state)
state = single_unkeyed_AES_round(state)
state = single_unkeyed_AES_round(state)
state = full_10_round_AES(key=key, message=state)
return stateAs another point of comparison, one may examine Alpha-MAC, a similar construction that instead absorbs 32-bit blocks of input into a 128-bit state by xoring them into four of the state bytes, then applying a single round of AES.
PELICAN and Alpha-MAC have received non-trivial cryptanalysis, and are not unscathed11, with attacks capitalizing on the greatly reduced number of AES rounds compared to CBC-MAC-AES. Note that both PELICAN and Alpha-MAC apply four AES rounds per 16 bytes absorbed, or four times as much AES per byte as Meow hash does.
AES depth
Let the AES depth of a circuit that takes in some inputs and produces some outputs be defined as:
\[\text{AES depth} = \max_{\text{input node, output node}} \,\, \max_{\text{path from input node to output node}} \,\, \text{number of AES rounds along the path}\]The AES depth of a circuit directly affects the highest degree terms that appear in it (as a polynomial over GF(2)), and is a relevant figure of merit for estimating the security12.
The rate at which AES depth accumulates in a design is controlled by how quickly AES’s output feeds back into its input. Let us compare two of the above constructions to Meow hash, in particular highlighting said tightest feedback loop through AES:
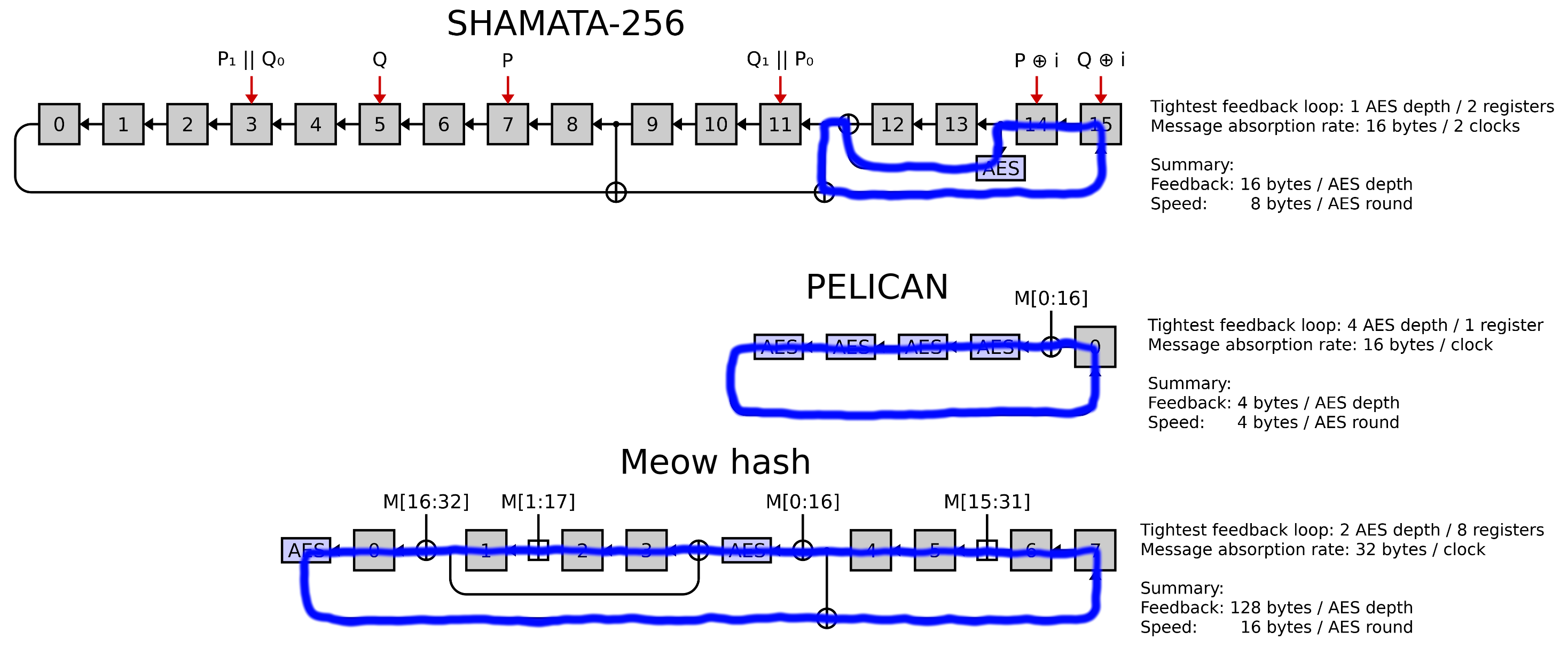
The ratio of AES rounds to registers in this feedback loop controls the rate at which AES’s output feeds back into its input, and thus sets the rate at which AES depth accumulates as you clock the construction. As we can see from the above diagram, SHAMATA-256 and PELICAN both feed AES’s output back into its input very rapidly, and accumulate one round of AES depth every 16 message bytes and 4 message bytes respectively.
Meow hash, however, takes a very long time to feed the output of AES back into AES, and therefore accumulates a round of AES depth only every 128 bytes of input on average.
I assume this was an intentional design decision by the Meow hash folks to combat the latency of the aesdec instruction and maximize pipeline efficiency, but they have gone quite far in this direction, and security will likely suffer substantially.
From the above figure we see that Meow hash both runs at the highest speed (i.e. fewest AES rounds per input byte), and takes by far the longest to accumulate AES depth of the three constructions under examination. Again, this slow feedback allows several aesdec instructions to be in flight at once, which, when combined with the low number of total AES rounds per byte, enables Meow hash to hash at extremely high speeds; the trade-off is almost certainly greatly reduced security.
In conclusion, by comparison to peer hash and MAC functions it seems rather implausible that Meow hash could be secure as a cryptographic hash (which they were not aiming to be), and also dubious that it would be secure as a MAC, even with small tweaks to fix the vulnerabilities outlined earlier in this document. To reiterate, if Meow hash were secure as a MAC it would be doing so with only a fraction (25%) of the AES rounds compared to some other well-studied AES-based MACs.
Finalization rounds: AES depth
TL;DR: No invalidation, low heebie-jeebies. Meow hash’s finalization rounds can be thought of as applying approximately five rounds of AES per input lane, except for lane 3, which sort of only receives four. Four rounds of AES is pretty non-ideal.
Let the min AES depth of a circuit that takes in some inputs and produces some outputs be defined as:
\[\text{min AES depth} = \min_{\text{input node, output node}} \,\, \max_{\text{path from input node to output node}} \,\, \text{number of AES rounds along the path}\]This definition differs from our notion of AES depth from before in that we minimize over input/output nodes, rather than maximizing. This minimization corresponds to an attacker having freedom to pick the weakest inputs to manipulate in their attack, and to probe for deviations in the weakest output. A high min AES depth indicates that the worst case path from inputs to outputs still receives many rounds of AES.
What is the min AES depth of Meow hash’s finalization as a function of number of rounds? We can compute these shortest longest paths via dynamic programming:
import numpy as np
def xor(x, y):
depths[x] = np.maximum(depths[x], depths[y])
addq = xor
def aesdec(x, y):
depths[x] += 1
xor(x, y)
def meow_shuffle(r1, r2, r3, r4, r5, r6):
aesdec(r1, r4)
addq(r2, r5)
xor(r4, r6)
aesdec(r4, r2)
addq(r5, r6)
xor(r2, r3)
for round_count in range(0, 13):
# depths[lane_out][lane_in] corresponds to the highest number of AES rounds an
# input bit from lane_in could have passed through to affect lane_out so far.
# The placeholder value -100 indicates that there is no path from lane_in to lane_out yet.
depths = (np.eye(8, dtype=np.int32) - 1) * 100
# Apply the finalization rounds.
for i in range(round_count):
lanes = i + np.array([0, 1, 2, 4, 5, 6])
lanes %= 8
meow_shuffle(*lanes)
# Aggregate the lanes down into lane 0.
# This isn't how aggregation actually works, but it's equivalent for this analysis.
for i in range(1, 8):
xor(0, i)
print(
"With %2i rounds, depth by input lane: %s -- min AES depth: %s"
% (round_count, depths[0], min(depths[0]))
)The above program outputs:
With 0 rounds, depth by input lane: [0 0 0 0 0 0 0 0] -- min AES depth: 0
With 1 rounds, depth by input lane: [1 0 0 0 1 0 1 0] -- min AES depth: 0
With 2 rounds, depth by input lane: [1 1 1 0 1 1 1 1] -- min AES depth: 0
With 3 rounds, depth by input lane: [2 1 1 1 1 1 1 1] -- min AES depth: 1
With 4 rounds, depth by input lane: [2 2 2 1 2 2 2 1] -- min AES depth: 1
With 5 rounds, depth by input lane: [2 2 2 2 2 2 2 2] -- min AES depth: 2
With 6 rounds, depth by input lane: [3 2 2 2 3 2 3 2] -- min AES depth: 2
With 7 rounds, depth by input lane: [3 3 3 2 3 3 3 3] -- min AES depth: 2
With 8 rounds, depth by input lane: [4 3 3 3 3 3 3 3] -- min AES depth: 3
With 9 rounds, depth by input lane: [4 4 4 3 4 4 4 3] -- min AES depth: 3
With 10 rounds, depth by input lane: [4 4 4 4 4 4 4 4] -- min AES depth: 4
With 11 rounds, depth by input lane: [5 4 4 4 5 4 5 4] -- min AES depth: 4
With 12 rounds, depth by input lane: [5 5 5 4 5 5 5 5] -- min AES depth: 4
Here each row shows the AES depth of each input lane, with the overall AES depth being the minimum across these values.
For example, the final row reads [5 5 5 4 5 5 5 5].
This means that every lane except lane 3 has a path to affect the output that passes through five rounds of AES.
However, lane 3’s longest path only goes through four rounds of AES.
It should be noted that five rounds of AES is know to be pretty weak, and four rounds of AES has deep weaknesses (lots of impossible characteristics, key recovery attacks, etc.). However, the final aggregation down to a single lane consisting of alternating additions and xors helps a fair amount in smoothing out observable non-idealities in four rounds of AES, as we will see later.
A second-order differential attack on Meow hash’s finalization
TL;DR: No invalidation, mild heebie-jeebies. Meow hash’s finalization rounds survive some rudimentary differential cryptanalysis, but not by an enormous margin.
Another common technique is to differentiate multiple times, and examine e.g.:
\[f_{\Delta_0, \Delta_1}(x) = f(x) \oplus f(x \oplus \Delta_0) \oplus f(x \oplus \Delta_1) \oplus f(x \oplus \Delta_0 \oplus \Delta_1)\]I found such a second-order differential attack to work better on Meow hash’s finalization rounds than the first-order ones I tried. So we will perform a cursory truncated second-order differential analysis of Meow hash, searching over one-bit values of \(\Delta_0\), and always fixing \(\Delta_1\) equal to \(\Delta_0\) shifted by 64 bits (I tried several shift values and 64 yielded the best results). We will examine if any of the bits of \(f_{\Delta_0, \Delta_1}\) are biased towards disproportionately being 0s or 1s for various numbers of rounds.
First, we make a modified version of the Meow hash header, called meow_hash_x64_aesni_early_out.h, that allows us to experiment with reduced round variants.
This header listens to four macros:
FINALIZATION_ROUNDS: Defined from 0 to 12, sets the number of rounds to apply in the blue region.MIX_RESIDUALS_IN: Either 0 or 1, and sets whether the rounds in the green region are applied.INCULDE_AGGREGATION: Either 0 or 1, and sets whether the seven operations in the pink region are applied.XOR_INSTEAD_OF_ADD: Either 0 or 1, and sets whether to replace the additions in Meow hash with xors, to make it more vulnerable to differential cryptanalysis.
Additionally, the MeowHash function is modified to take a pointer to dump the entire 128-byte state to, rather than merely returning the first lane.
Using this header we can investigate differential cryptanalysis:
#include <stdint.h>
#include <stdio.h>
#include <string.h>
#include <math.h>
#define FINALIZATION_ROUNDS 7
#define MIX_RESIDUALS_IN 0
#define INCLUDE_AGGREGATION 1
#define XOR_INSTEAD_OF_ADD 0
#include "meow_hash_x64_aesni_early_out.h"
#define SAMPLES 10000
#if INCLUDE_AGGREGATION
# define OUTPUT_BITS_TESTED 128
#else
# define OUTPUT_BITS_TESTED 1024
#endif
#define KEY_SIZE 128
static void flip_bit(uint8_t* memory, int bit_index) {
memory[bit_index / 8] ^= 1 << (bit_index % 8);
}
int main() {
uint8_t output_buffer[KEY_SIZE];
uint8_t hash_scratch_space0[KEY_SIZE];
uint8_t hash_scratch_space1[KEY_SIZE];
uint8_t hash_scratch_space2[KEY_SIZE];
uint8_t hash_scratch_space3[KEY_SIZE];
uint64_t rng_scratch_space[16] = {0};
uint64_t key_scratch_space[16] = {0};
int difference_counts[OUTPUT_BITS_TESTED * 1024] = {0};
#define DIF_COUNT(IN_POSITION, OUT_POSITION) (difference_counts[(OUT_POSITION) + OUTPUT_BITS_TESTED * (IN_POSITION)])
// Our goal is to evaluate:
// f(x) + f(x + delta0) + f(x + delta1) + f(x + delta0 + delta1)
// where delta1 = delta0 << 64, for every one bit delta0 averaged across many input values x.
for (int counter = 0; counter < SAMPLES; counter++) {
// Use Meow hash as a PRNG to generate a random key.
rng_scratch_space[0] = counter;
MeowHash(rng_scratch_space, 0, NULL, (meow_u128*) key_scratch_space);
// Get the hash.
MeowHash(key_scratch_space, 0, NULL, (meow_u128*) hash_scratch_space0);
for (int input_position = 0; input_position < 1024 - 64; input_position++) {
// Compute key_scratch_space = x + delta0, then hash.
flip_bit(key_scratch_space, input_position);
MeowHash(key_scratch_space, 0, NULL, (meow_u128*) hash_scratch_space1);
// Compute key_scratch_space = x + delta0 + delta1, then hash.
flip_bit(key_scratch_space, input_position + 64);
MeowHash(key_scratch_space, 0, NULL, (meow_u128*) hash_scratch_space2);
// Compute key_scratch_space = x + delta1, then hash.
flip_bit(key_scratch_space, input_position);
MeowHash(key_scratch_space, 0, NULL, (meow_u128*) hash_scratch_space3);
// Compute hash_scratch_space1 = f(x) + f(x + delta0) + f(x + delta0 + delta1) + f(x + delta1).
for (int i = 0; i < KEY_SIZE; i++)
hash_scratch_space1[i] ^= hash_scratch_space0[i] ^ hash_scratch_space2[i] ^ hash_scratch_space3[i];
// Log all the output bits that are set in this xor of hashes.
int output_position = 0;
_Static_assert(OUTPUT_BITS_TESTED % 64 == 0);
for (int i = 0; i < (OUTPUT_BITS_TESTED / 64); i++) {
uint64_t block = ((uint64_t*) hash_scratch_space1)[i];
for (int j = 0; j < 64; j++) {
DIF_COUNT(input_position, output_position) += block & 1;
block >>= 1;
output_position++;
}
}
// Reset key_scratch_space = x, to be ready for the next delta.
flip_bit(key_scratch_space, input_position + 64);
}
}
printf("Computed all differentials.\n");
int expected_difference_count = SAMPLES / 2;
// The standard deviation of a sample from a balanced binomial distribution is sqrt(n) / 2.
double standard_deviation = 0.5 * sqrt(SAMPLES);
// We now analyze the difference counts for any statistical deviations.
for (int input_position = 0; input_position < 1024 - 64; input_position++) {
for (int output_position = 0; output_position < OUTPUT_BITS_TESTED; output_position++) {
double z_score = (DIF_COUNT(input_position, output_position) - expected_difference_count) / standard_deviation;
if (fabs(z_score) > 6) {
printf(
"Statistical deviation: input-position=%i output-position=%i z-score=%f (count: %i)\n",
input_position, output_position, z_score, DIF_COUNT(input_position, output_position)
);
}
}
}
}We will answer two questions:
- How many finalization rounds are needed before Meow hash’s internal state (before aggregation) is free from this family of one-bit truncated second-order differential characteristics?
- How many finalization rounds are needed before the final output hash (after aggregation) is free from these characteristics?
To answer the first question we set FINALIZATION_ROUNDS = 10, INCLUDE_AGGREGATION = 0, and OUTPUT_BITS_TESTED = 1024.
We will find that the above program immediately finds all sorts of completely blatant characteristics (output bits of \(f_{\Delta_0, \Delta_1}\) that were almost always zero).
If we raise FINALIZATION_ROUNDS to 11 then these characteristics go away.
To answer the second question we set FINALIZATION_ROUNDS = 7, INCLUDE_AGGREGATION = 1, and OUTPUT_BITS_TESTED = 128.
We will find that the above program detects blatant biases, but these go away with FINALIZATION_ROUNDS = 8.
Ultimately, this analysis shows that having many finalization rounds (≥8) is critical for Meow hash’s finalization to avoid detectable biases. Simply guaranteeing that every lane passes through two or three rounds of AES is insufficient.
I should emphasize that the above analysis is relatively rudimentary, and also that this line of attack assumes the ability to inject these deltas into the state (which is not trivial). However, I leave these issues unexplored; I stopped once I started having great success attacking the absorption function. Future work on the finalization rounds might include finding ways to injected the required deltas, and importing state-of-the-art characteristics known for AES.
Can we make differences in the message trivially cancel out in absorption?
TL;DR: No invalidation, no heebie-jeebies. The way Meow hash absorbs the message is free from simple vanishing differential characteristics with no active sboxes.
We have already found a vanishing characteristic in Meow hash that involves three active sboxes, and has probability \(2^{-45}\) because of all of the guessing required. When looking at how Meow hash absorbs the message, one immediately wonders if there is a way to inject differences that cancel internally (a vanishing characteristic) without ever entering AES, thus avoiding any active sboxes. This would correspond to clicking on a subset of boxes in the above interactive diagram in which all the red wires cancel out, and no red wire ever enters AES becoming an unmanageable yellow wire.
To answer this question we will abstractly model a differential version of Meow hash’s absorption function in a SAT instance, and ask for such a vanishing characteristic. In particular, our differential model of Meow hash will be searching for a message difference \(\Delta\), that entirely cancels out during absorption.
In our SAT instance each byte in each lane will be modeled as a single variable, with 0 indicating no difference between the two evaluations of the absorption function, and 1 indicating a difference. We construct a SAT instance via the following Python:
from typing import List
import numpy as np
# We implement 1000 blocks of absorbing 32 bytes of message each, thus asking if there's
# any Δ of at most 32,000 bytes that cancels out internally. This should be sufficient.
MEOW_MIX_COUNT = 1000
# We define a helper class for making DIMACS format SAT instances.
class Instance:
def __init__(self):
self.variables = 0
self.clauses = []
def new_var(self) -> int:
self.variables += 1
return self.variables
def add_clause(self, variables, prefix=""):
self.clauses.append(prefix + " ".join(map(str, variables)) + " 0")
def make_dimacs(self) -> str:
return "p cnf %i %i\n%s\n" % (
self.variables, len(self.clauses), "\n".join(self.clauses),
)
inst = Instance()
# Each of these message variables is 1 if we're injecting a difference in that message byte, and 0 otherwise.
message_vars = [inst.new_var() for _ in range(32 * MEOW_MIX_COUNT)]
# Create variables saying which bytes of internal state contain differences.
lanes = [
[inst.new_var() for _ in range(16)]
for _ in range(8)
]
def force_to_zero(variables: List[int]):
for var in variables:
inst.add_clause([-var])
def xor_into_lane(dest_lane: int, variables: List[int]):
new_lane = [inst.new_var() for _ in range(16)]
for a, b, c in zip(lanes[dest_lane], variables, new_lane):
# Here x is a non-standard cryptominisat DIMACS extension for an xor constraint between variables.
inst.add_clause([a, b, -c], prefix="x ")
lanes[dest_lane] = new_lane
def xor_in_message(dest_lane: int, message_address: int):
xor_into_lane(dest_lane, message_vars[message_address : message_address + 16])
# For this analysis we ignore carries in addition, and treat it as xor; you can often guess them anyway.
add_in_message = xor_in_message
def aesdec(dest_lane: int, source_lane: int):
# We don't want any active sboxes ever, so force the lane to be all zeros (have no differences).
force_to_zero(lanes[dest_lane])
xor_into_lane(dest_lane, lanes[source_lane])
def meow_mix(r1: int, r2: int, r3: int, r4: int, r5: int, address: int):
aesdec(r1, r2)
add_in_message(r3, address + 0x0f)
xor_in_message(r2, address + 0x00)
aesdec(r2, r4)
add_in_message(r5, address + 0x01)
xor_in_message(r4, address + 0x10)
# We start with no differences.
for lane in lanes:
force_to_zero(lane)
# Model the hash function absorbing the message blocks.
for round_number in range(MEOW_MIX_COUNT):
lanes = (round_number + np.array([0, 4, 6, 1, 2])) % 8
meow_mix(*lanes, address = 0x20 * round_number)
# Whatever differences we've created must be canceled out by the end.
for lane in lanes:
force_to_zero(lane)
# Finally, disallow the trivial solution where all message bytes have no deltas injected.
inst.add_clause(message_vars)
with open("out.dimacsx", "w") as f:
f.write(inst.make_dimacs())This SAT instance has 128,128 variables and 128,257 clauses, and yet cryptominisat5 reports that it’s unsatisfiable in a fraction of a second; we conclude that Meow hash’s message absorption survives this test, and there is no trivial way to get message differences to cancel.
If the Meow hash folks attempt to patch up their message absorption scheme I would encourage them to sanity-check any changes via this approach, if they were not already using equivalent methods.
Square attack
TL;DR: No invalidation, low heebie-jeebies. If Meow hash had only 5 finalization rounds then a simple square attack would reveal biases. However, it has 12.
The AES round function is relatively subject to the so-called square attack (also sometimes known as integral cryptanalysis). This attack is a variant and generalization of differential cryptanalysis; I will summarize it at a very high level here, but I will omit proofs or explanation of some of the claimed properties.
Given an ensemble of equal-length blocks of bytes, let the ensemble’s cardinality at byte i be the number of distinct values taken on at byte position i across the ensemble. In Python:
def cardinality(ensemble_of_byte_blocks: List[bytes], i: int) -> int:
return len(set(block[i] for block in ensemble_of_byte_blocks))Given an ensemble of blocks, we will say that byte i is saturated if the cardinality at i is 256.
Much like in differential cryptanalysis, where we examine only how operations in our cryptosystem affect our differential characteristic, we will now abstract over the particular values in our ensemble, and examine only how operations applied to each block in our ensemble in parallel change the cardinalities of particular bytes.
Some properties of this style of differential cryptanalysis, given without proof:
- Xoring a constant into the block doesn’t affect any cardinalities.
- Adding a constant into each byte doesn’t affect any cardinalities.
- Applying an sbox to each byte doesn’t affect any cardinalities; nor does applying any bijective mapping to any byte.
- Adding a 64-bit constant into a 64-bit subword of the block can change cardinalities, but only by carries propagating across byte boundaries, so the effect is somewhat limited. We will neglect this effect in some of the following analysis.
- Any bytes read from elsewhere in the state with cardinality 1 may be treated as a constant for the purposes of the above rules.
- Adding/xoring a byte of cardinality c into a byte of cardinality 1 results in both bytes ending with cardinality c.
- Applying the AES mix-columns operation to a column with one saturated byte and the rest of cardinality 1 results in the entire column ending saturated.
- … and many other such interesting properties.
Observe that plain old differential cryptanalysis is a special case of this analysis technique, where bits take the place of bytes (so the only possible cardinalities are 1 and 2), and the ensemble has only two members.
With this nomenclature and these properties in mind, construct an ensemble of 256 16-byte blocks that are saturated at byte 0, and whose cardinality is 1 at every other byte. For example, the ensemble might be:
[
hex_to_bytes("00000000000000000000000000000000"),
hex_to_bytes("01000000000000000000000000000000"),
hex_to_bytes("02000000000000000000000000000000"),
...
hex_to_bytes("ff000000000000000000000000000000"),
]
We will examine the effect of two applications of the AES round function on this ensemble, where the values in the below diagram now indicate the cardinality of the byte across the ensemble:
In short, two rounds of AES (either encryption or decryption) when applied to an ensemble of the above form results in an ensemble where every byte is saturated. If we apply one more round of AES then saturated bytes will interact with other saturated bytes in the mix-columns step, and won’t remain necessarily saturated. Much like in vanilla differential cryptanalysis, when differing bits interact non-linearly with other differing bits, the results are now dependent on the actual values in the ensemble, and the effects can only be described stochastically.
How does this apply to Meow hash? Let us examine the complete network for Meow hash evaluated on a 256-byte message:
As a reminder:
- The red region absorbs the message block.
- The green region absorbs a finalization block that includes the message length. The details are unimportant for this analysis, just know that the values
R0throughR7are all independent of the message (assuming the message length is fixed at 256 bytes). - The blue region is the finalization rounds.
- The pink region aggregates the state down into a single output lane.
Observe that the first and last byte of each 32-byte block in the message is xored into the state in a single place. Therefore, if we construct an ensemble of messages that are saturated at the first or last byte of some 32-byte block, and have cardinality 1 everywhere else, then immediately after the xor that reads this saturated byte is completed the state of our hash function will be saturated at one byte, and cardinality 1 everywhere else — the perfect setup for a square attack.
We will now diagram the effects of injecting saturation into Meow hash, as described above. In the following diagrams let:
- Teal represent a lane that is saturated at one byte, and has cardinality 1 at all others. (Referred to as a Λ-set in the original square paper.)
- Red represent a lane that is saturated at four bytes, and has cardinality 1 at all others.
- Green represent a lane that is saturated at all sixteen bytes.
- Yellow represent a lane about which we can make static claims about the saturation of some bytes, but the saturation of other bytes depends on the specific values in the ensemble.
- Blue represent a lane where we cannot statically make any claims about the saturation of any bytes.
Here is the effect of injecting saturation into the byte at position 0xdf in the message block:

Here is the hypothetical effect of injecting saturation into the byte at position 0xf0 in the message block, if we could somehow prevent the read labeled 0xf0 from seeing this saturation:

I implemented a search over applying the square attack to every message byte in any message of length up to 512 bytes, and it shows biases in the state during finalization after 9 rounds without aggregation, and biases after 5 rounds in what would be the final hash value (if aggregation were instead performed after only 5 rounds) — these results are inferior to the second-order differential cryptanalysis, so I have pushed the attack code to the appendix.
However, our second-order differential cryptanalysis assumed (unrealistically) that we could inject our desired deltas into the state before finalization. This square attack works against the actual (reduced round) hash function directly by saturating bytes in the message, thus showing that Meow hash with only 5 finalization rounds would be broken in practice, even though 5 finalization rounds is enough to ensure min AES depth of 2.
SAT solving for collisions between messages of different lengths
Due to Meow hash’s out-of-order message absorption, it might be possible to use SAT solving to symmetrize the state after the message length has been absorbed, but before some addition block of input has been absorbed. If one then fixes this additional block of input to be abc-symmetrical then the final hash will only have 64 bits of entropy. By applying a standard low-memory collision attack (that would take a few minutes) it would then be possible to find blocks to append to cause arbitrary messages to collide under a known key, much like how we found collisions in the “Collisions from symmetry” section.
However, my SAT instances that have attempted to symmetrize the state including the message length block so far have failed to solve with ~750 hours of time. But I think this line of attack would be promising for future work.
Appendix
All code in this document is released into the public domain.
Meow hash reference implementation
I release the following reference implementation of Meow hash in Python 3 into the public domain:
import struct
meow_default_seed = bytes.fromhex(
"3243f6a8885a308d313198a2e03707344a4093822299f31d0082efa98ec4e6c8"
"9452821e638d01377be5466cf34e90c6cc0ac29b7c97c50dd3f84d5b5b547091"
"79216d5d98979fb1bd1310ba698dfb5ac2ffd72dbd01adfb7b8e1afed6a267e9"
"6ba7c9045f12c7f9924a19947b3916cf70801f2e2858efc16636920d871574e6"
)
aes_sbox_inverse = list(bytes.fromhex(
"52096ad53036a538bf40a39e81f3d7fb7ce339829b2fff87348e4344c4dee9cb"
"547b9432a6c2233dee4c950b42fac34e082ea16628d924b2765ba2496d8bd125"
"72f8f66486689816d4a45ccc5d65b6926c704850fdedb9da5e154657a78d9d84"
"90d8ab008cbcd30af7e45805b8b34506d02c1e8fca3f0f02c1afbd0301138a6b"
"3a9111414f67dcea97f2cfcef0b4e67396ac7422e7ad3585e2f937e81c75df6e"
"47f11a711d29c5896fb7620eaa18be1bfc563e4bc6d279209adbc0fe78cd5af4"
"1fdda8338807c731b11210592780ec5f60517fa919b54a0d2de57a9f93c99cef"
"a0e03b4dae2af5b0c8ebbb3c83539961172b047eba77d626e169146355210c7d"
))
def gf_multiply(a: int, b: int) -> int:
r = 0
for i, bit in enumerate(bin(b)[-1:1:-1]):
r ^= int(bit) * (a << i)
while r.bit_length() > 8:
r ^= 0x11b << (r.bit_length() - 9)
return r
gf_table = {(a, b): gf_multiply(a, b) for a in (9, 11, 13, 14) for b in range(256)}
def inverse_mix_column(col: bytearray):
a, b, c, d = col
return (
gf_table[14, a] ^ gf_table[11, b] ^ gf_table[13, c] ^ gf_table[ 9, d],
gf_table[ 9, a] ^ gf_table[14, b] ^ gf_table[11, c] ^ gf_table[13, d],
gf_table[13, a] ^ gf_table[ 9, b] ^ gf_table[14, c] ^ gf_table[11, d],
gf_table[11, a] ^ gf_table[13, b] ^ gf_table[ 9, c] ^ gf_table[14, d],
)
def aesdec(a: bytearray, b: bytearray):
# Inverse shift rows.
for row_index in range(4):
row = a[row_index::4]
for _ in range(row_index):
row = row[-1:] + row[:-1]
a[row_index::4] = row
# Inverse sbox.
for i in range(16):
a[i] = aes_sbox_inverse[a[i]]
# Inverse mix columns.
for column_index in range(4):
a[column_index*4 : column_index*4 + 4] = \
inverse_mix_column(a[column_index*4 : column_index*4 + 4])
# Xor round key.
for i in range(16):
a[i] ^= b[i]
def paddq(a: bytearray, b: bytearray):
mask64 = 2**64 - 1
a0, a1 = struct.unpack("<QQ", a)
b0, b1 = struct.unpack("<QQ", b)
a[:] = struct.pack("<QQ", (a0 + b0) & mask64, (a1 + b1) & mask64)
def pxor(a: bytearray, b: bytearray):
for i in range(16):
a[i] ^= b[i]
def meow_hash(key_bytes: bytes, input_bytes: bytes) -> bytes:
assert len(key_bytes) == 128
lanes = [
bytearray(key_bytes[i*16 : i*16 + 16])
for i in range(8)
]
get_lane = lambda i: lanes[i % 8]
def meow_mix_reg(i, reads):
aesdec(get_lane(i + 0), get_lane(i + 4))
paddq (get_lane(i + 6), reads[0])
pxor (get_lane(i + 4), reads[1])
aesdec(get_lane(i + 4), get_lane(i + 1))
paddq (get_lane(i + 2), reads[2])
pxor (get_lane(i + 1), reads[3])
def meow_mix(i, block):
meow_mix_reg(i, [
block[offset : offset + 16] for offset in (15, 0, 1, 16)
])
def meow_mix_funky(i, block):
meow_mix_reg(i, (
b"\0" + block[:15], block[:16], block[17:] + block[:1], block[16:],
))
def meow_shuffle(i):
aesdec(get_lane(i + 0), get_lane(i + 4))
paddq (get_lane(i + 1), get_lane(i + 5))
pxor (get_lane(i + 4), get_lane(i + 6))
aesdec(get_lane(i + 4), get_lane(i + 1))
paddq (get_lane(i + 5), get_lane(i + 6))
pxor (get_lane(i + 1), get_lane(i + 2))
# Pad the input to a multiple of 32 bytes; but add a full block of zeros if we're already a multiple.
original_length = len(input_bytes)
target_length = ((len(input_bytes) // 32) + 1) * 32
input_bytes += b"\0" * (target_length - original_length)
# Cut off the last block, which we will absorb differently.
input_bytes, tail_block = input_bytes[:-32], input_bytes[-32:]
# Absorb all complete 256-byte blocks.
off = 0
while off + 256 <= len(input_bytes):
for _ in range(8):
meow_mix(off // 32, input_bytes[off : off+32])
off += 32
# Absorb the tail block and message length in a funky way that's different than all other absorptions.
meow_mix_funky(0, tail_block)
message_length_block = struct.pack("<QQQQ", 0, 0, original_length, 0)
meow_mix_funky(1, message_length_block)
# Now return to absorbing any remaining 32-byte blocks.
while off + 32 <= len(input_bytes):
meow_mix(2 + off // 32, input_bytes[off : off + 32])
off += 32
# Finalize.
for i in range(12):
meow_shuffle(i)
# Aggregate the state down into a single lane.
paddq(lanes[0], lanes[2])
paddq(lanes[4], lanes[6])
paddq(lanes[1], lanes[3])
paddq(lanes[5], lanes[7])
pxor(lanes[0], lanes[1])
pxor(lanes[4], lanes[5])
paddq(lanes[0], lanes[4])
return lanes[0]Full key recovery code
#include <cstdint>
#include <cstdio>
#include <cstring>
#include <vector>
#include "meow_hash_x64_aesni.h"
// We define MeowHashAbstractedAttack(length, message, block_count) to be the subroutine
// that performs our partial key recovery attack ("reading the indicator byte"), and returning it.
// In particular, MeowHashAbstractedAttack returns the top byte of lane 1 after `block_count` number
// of 32-byte blocks have been absorbed while hashing `message` under some secret key.
static void flip_bit(uint8_t* memory, int bit_index) {
memory[bit_index / 8] ^= 1 << (bit_index % 8);
}
struct Observation {
int blocks_to_skip;
int lane_index;
int byte_index;
uint8_t value;
};
constexpr int MESSAGE_LEN = 512;
static void apply_aes(uint8_t* mem) {
__m128i x = _mm_loadu_si128((__m128i*) mem);
x = _mm_aesdec_si128(x, _mm_setzero_si128());
_mm_storeu_si128((__m128i*) mem, x);
}
#define CLEAR_MESSAGE memset(message, 0, MESSAGE_LEN)
void generate_observations(
std::vector<Observation>& observations
) {
uint8_t message[MESSAGE_LEN];
// Build lookup tables of how deltas into AES affect our indicator byte.
uint16_t delta_lookup_table[4 * 256 * 256];
for (int i = 0; i < 4 * 256 * 256; i++)
delta_lookup_table[i] = 0xffff;
for (int position = 0; position < 4; position++) {
for (int byte_value = 0; byte_value < 256; byte_value++) {
uint8_t block[16];
uint8_t values[3];
for (int i = 0; i < 3; i++) {
memset(block, 0, 16);
block[3 + 3 * position] = byte_value ^ i;
apply_aes(block);
values[i] = block[15];
}
uint32_t delta0 = values[0] ^ values[1];
uint32_t delta1 = values[0] ^ values[2];
uint32_t key = (position << 16) | (delta0 << 8) | (delta1 << 0);
// Assert that there isn't any ambiguity. If there were, we'd need to change the deltas we use.
assert(delta_lookup_table[key] == 0xffff);
delta_lookup_table[key] = byte_value;
}
}
for (int rep = 0; rep < 8; rep++) {
// === Full recovery phases 1 and 2:
// Perform an attack based on addition in the round before the read byte.
// Reads bytes [8:16] in lane: rep + 2.
{
CLEAR_MESSAGE;
uint8_t base_byte = MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 1);
observations.push_back({rep, rep + 2, 15, base_byte});
// We now attempt to determine the bits of lower bytes.
for (int bit = 8 * 7 - 1; bit >= 0; bit--) {
flip_bit(message + 32 * rep + 9, bit);
uint8_t attack_value = MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 1);
if (attack_value != base_byte) {
flip_bit(message + 32 * rep + 9, bit);
}
}
for (int i = 0; i < 7; i++) {
observations.push_back({
rep,
rep + 2,
8 + i,
message[32 * rep + 9 + i] ^ 0xff,
});
}
}
// === Full recovery phase 3:
// Perform an attack based on the effects of XOR into AES three rounds before the read byte.
// Reads bytes 3, 6, 9, 12 in lane: rep + 4.
{
CLEAR_MESSAGE;
uint8_t base_byte = MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 3);
for (int position = 0; position < 4; position++) {
CLEAR_MESSAGE;
message[32 * rep + 3 + 3 * position] ^= 1;
uint32_t delta0 = base_byte ^ MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 3);
message[32 * rep + 3 + 3 * position] ^= 3;
uint32_t delta1 = base_byte ^ MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 3);
uint32_t key = (position << 16) | (delta0 << 8) | (delta1 << 0);
uint16_t result = delta_lookup_table[key];
assert(result != 0xffff);
observations.push_back({
rep,
rep + 4,
3 + 3 * position,
result ^ base_message[32 * rep + 3 + 3 * position],
});
}
}
// === Full recovery phase 4:
// Perform an attack based on the effects of additions two rounds before the above attack.
// Reads bytes 0, 1, 2, 4, 5, 8, 10, 11 in lane: rep + 6
{
CLEAR_MESSAGE;
uint8_t base_byte = MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 5);
for (int position = 0; position < 4; position++) {
CLEAR_MESSAGE;
int lut[4] = {3, 2, 1, 2};
int bytes_to_recover = lut[position];
int message_offset = 15 + 3 + 3 * position - bytes_to_recover;
for (int bit = 8 * bytes_to_recover - 1; bit >= 0; bit--) {
flip_bit(message + 32 * rep + message_offset, bit);
uint8_t attack_value = MeowHashAbstractedAttack(MESSAGE_LEN, message, rep + 5);
if (attack_value != base_byte) {
flip_bit(message + 32 * rep + message_offset, bit);
}
}
for (int i = 0; i < bytes_to_recover; i++) {
observations.push_back({
rep,
rep + 6,
3 + 3 * position - bytes_to_recover + i,
message[32 * rep + message_offset + i] ^ 0xff,
});
}
}
}
}
}Square attack code
#include <stdint.h>
#include <stdio.h>
#include <string.h>
#define FINALIZATION_ROUNDS 5
#define MIX_RESIDUALS_IN 1
#define INCLUDE_AGGREGATION 1
#define XOR_INSTEAD_OF_ADD 0
#include "meow_hash_x64_aesni_early_out.h"
#define ATTEMPTS_PER_CONFIGURATION 100
#define MAX_INPUT_LENGTH 512
#if INCLUDE_AGGREGATION
# define OUTPUT_POSITIONS_TESTED 16
#else
# define OUTPUT_POSITIONS_TESTED 128
#endif
#define KEY_SIZE 128
int main() {
uint8_t* ensemble_results[256];
for (int i = 0; i < 256; i++)
ensemble_results[i] = malloc(KEY_SIZE);
uint8_t input_buffer[MAX_INPUT_LENGTH] = {0};
uint64_t key[16];
memcpy(key, MeowDefaultSeed, 128);
for (int input_length = 1; input_length <= MAX_INPUT_LENGTH; input_length++) {
printf("Testing input-length=%i\n", input_length);
for (int input_position = 0; input_position < input_length; input_position++) {
for (uint64_t counter = 0; counter < ATTEMPTS_PER_CONFIGURATION; counter++) {
memset(input_buffer, 0, input_length);
// Modify the key a little bit to depend on our counter, to get multiple attempts if the attack isn't reliable.
key[0] = 12345 * counter;
// Evaluate Meow hash on the entire ensemble, saving all the results.
for (int ensemble_value = 0; ensemble_value < 256; ensemble_value++) {
input_buffer[input_position] = ensemble_value;
// This is a modified version of the MeowHash function that takes a pointer to dump the entire state to.
MeowHash(key, input_length, input_buffer, (meow_u128*) ensemble_results[ensemble_value]);
}
// Count up the cardinality across the ensemble at each output position.
for (int output_position = 0; output_position < OUTPUT_POSITIONS_TESTED; output_position++) {
int hits[256] = {0};
for (int ensemble_value = 0; ensemble_value < 256; ensemble_value++)
hits[ensemble_results[ensemble_value][output_position]]++;
int cardinality = 0;
for (int i = 0; i < 256; i++)
cardinality += hits[i] != 0;
// The expected cardinality is 256 * (1 - (1 - 1 / 256)**256) ≈ 162.
// If the cardinality is at least 30 away then we print this unlikely event.
if (cardinality <= 132 || cardinality >= 192) {
printf(
"Hit: counter=%llu input-length=%i input-position=%i output-position=%i cardinality=%i\n",
counter, input_length, input_position, output_position, cardinality
);
}
}
}
}
}
}Footnotes
-
It turns out that the very last message block and message length block are absorbed slightly differently from all other blocks. If you are interested, check out the reference implementation of Meow hash in the appendix. ↩ ↩2
-
Of course, Floyd’s algorithm is several times slower than collision finding using distinguished points. I instead use Floyd’s algorithm here because it’s so short and sweet. ↩
-
In particular, \(f_\Delta\) should look like a random degree \(m - 1\) polynomial if \(f\) is random. The degree went down by one because we effectively took a derivative. For example, if \(\Delta\) is just a single bit then \(f_\Delta\) consists of all of the monomials of \(f\) that include that bit \(\Delta\), but without that bit. Therefore, if \(f\) was random of degree \(m\) (i.e. contained every monomial randomly with 50:50 odds) then \(f_\Delta\), being a “subset” of \(f\), should be random of degree \(m - 1\). Also note that when \(\Delta\) is a single bit then \(f_\Delta\) is literally the derivative of \(f\) along said axis (even just as a polynomial over \(\mathbb{R}\)). ↩
-
In this interactive I model the additions as xors. In practice this is often a pretty reasonable assumption, because one can often just hope to guess/get lucky with the carries. We will do exactly this later. ↩
-
The cancellation of red differences with each other in the various xors and additions isn’t entirely sound. Two differences could both be known, but known to be unequal. However, the interactive diagram gives a best case analysis where such cancellation is always allowed. ↩
-
It’s \(2^{-7}\) per guessed active sbox instead of \(2^{-8}\) because the value of \(\text{sbox}[x] \oplus \text{sbox}[x \oplus \Delta]\) is the same for \(x = a\) and \(x = a \oplus \Delta\), and therefore if our characteristic involves feeding a particular delta into an sbox with \(x\) taking on some particular value \(a\) then our characteristic will necessarily also work for \(x = a \oplus \Delta\). ↩
-
We require that the bytes tested in the assert in
apply_vanishing_characteristicare zero to avoid generating carries that would disturb the characteristic, and of course that all of the writes are within bounds. Additionally, the bytes modified by the characteristic must all be absorbed contiguously, so they cannot be absorbed as part of the final padding block that is absorbed both differently and out of order with the rest of the message. ↩ -
I actually didn’t quite sample randomly — I forced byte 31 in the key to be 0, and chose all the rest randomly, because that byte must have one of two values in order for the characteristic to work on these particular messages. This sped up the search by a factor of \(2^7\). This also relates to a key recovery attack that we will discuss shortly. ↩
-
However, for some reason preimage attacks (targeting a symmetrical state) don’t seem much easier inside of the symmetrical subspace. ↩
-
https://link.springer.com/content/pdf/10.1007/978-3-642-05445-7_1.pdf ↩
-
It should be noted that this metric can be misleading. For example, if one simply split up a message stream into alternating blocks and hashed the odd and even blocks separately, then the depth would be half as great as simply hashing the original stream, but of course security would not be affected. This notion of AES depth is merely suggestive of the rate at which non-linear interactions compound upon themselves. ↩